
Как вытащить текст из сканированного документа – Как извлечь текст из сканированной страницы, чтобы не было рамки и чтобы чтобы править его в Worde? Пытаюсь это сделать
- Комментариев к записи Как вытащить текст из сканированного документа – Как извлечь текст из сканированной страницы, чтобы не было рамки и чтобы чтобы править его в Worde? Пытаюсь это сделать нет
- Разное
Как скопировать отсканированный текст 🚩 как выделить текст с середины слова 🚩 Программное обеспечение
Автор КакПросто!
Иногда требуется распознать ранее отсканированный, но необработанный документ, чтобы использовать данные для импортирования в другой электронный документ. Лучше всего с этим справится одна из программ пакета Microsoft Office, которая создана для работы со сканированными копиями документов.

Статьи по теме:
Вам понадобится
- Программное обеспечение Microsoft Office Document Imaging.
Инструкция
В качестве примера будет использоваться данная утилита из пакета программ версии 2003. Для ее запуска нажмите меню «Пуск» и выберите раздел «Все программы» (для версии Windows XP и новее) либо «Программы» (для более старых версий систем Windows). В открывшемся списке найдите элемент Microsoft Office и запустите Microsoft Office Document Imaging.
В главном окне программы нажмите верхнее меню «Файл» и выберите строку «Открыть». В окне «Открытие файла» необходимо указать расположение отсканированного документа (формат tif). После его выбора нажмите кнопку «Открыть» либо клавишу Enter.
Для выполнения операции распознавания текста необходимо воспользоваться внутренней командой «Распознать текст» из верхнего меню «Сервис» либо из верхнего меню «Файл» (в зависимости от версии программного обеспечения).
Распознанный текст можно легко скопировать в любой другой документ Microsoft Office. Не стоит забывать, что готовые к копированию участки текста переносятся в буфер обмена не так, как текст из обычного документа, есть некоторые правила. Например, невозможно скопировать текст, остановив выделение на середине слова, доведите его до последней буквы слова и выполните копирование.
Выделение текста осуществляется не маркерным типом, а рамочным. Для этого нажмите верхнее меню «Вид» и выберите пункт «Выделить» (изображение курсора). После определения куска текста, готового для копирования, нажмите верхнее меню «Правка» и выберите пункт «Копировать» либо воспользуйтесь контекстным меню данной страницы.
Перейдите к другому приложению Microsoft Office. Нажмите верхнее меню «Правка» и выберите пункт «Вставить» либо воспользуйтесь инструментом «Буфер обмена» из этого же меню. Также вставку скопированного фрагмента можно осуществить через контекстное меню текущего документа.
www.kakprosto.ru
Как из картинки вытащить текст в Word
Перед каждым пользователем ПК хоть раз возникала необходимость получения текстовой информации из картинок. Работая в программах для набора, иногда приходится перепечатывать текст, находящийся в растровом или векторном изображении. Этот долгий процесс можно сократить, если знать, как из картинки вытащить текст в Word.

Для преобразования текста на картинке в документ Ворд — следуйте инструкциям ниже
Выход из ситуации
Обычно процесс распознавания с изображения достаточно трудоёмкий. В нём основную работу придётся делать вручную, но конечный результат сэкономит общее затраченное время. Это бывает необходимо, когда в распоряжении присутствует только электронное изображение документа или страницы книги, с которой нужно вытащить текст.
Вместо собственноручного перепечатывания информации, можно воспользоваться специализированными программами и сервисами, которые автоматизируют эту работу. Они позволяют распознать текст, используя картинки большинства популярных форматов, среди которых jpg, gif и png.
Порядок работ
Если данные находятся на печатном документе, с него придётся предварительно сделать изображение. Для этого потребуется сканер. Также это бывает необходимо, если текст на картинке имеет плохое разрешение или он размытый. К сканеру должны прилагаться «родные» драйвера и программы, которые позволят перевести всё в высоком качестве. На результат влияет не только чёткость букв, но и их «ровное» положение, а также отсутствие помех.

Если вам необходимо получить текст с бумажного носителя — потребуется сканер
При неимении сканера можно обойтись фотоаппаратом. В этом случае потребуется правильно выставить свет. На следующем этапе требуется использование специальных программ, которые позволят непосредственно распознать текст с jpg. Среди таких программ особое место занимает ABBYY FineReader, которая считается лидером на рынке. Она платная, но её качество соответствует стоимости.
Особенности процесса
В функционале программного обеспечения присутствует много функций, позволяющих работать с большинством шрифтов. Среди передовых возможностей присутствует способность распознать рукописный текст Word из jpg. Она имеет много преимуществ:
- выбор качества. Пользователь может сам остановить предпочтительное качество для сканирования. Лучше выбирать не ниже 300 DPI, чтобы программа затрагивала для обработки даже мелкие детали, и смогла работать с мелкими шрифтами.
- цветность. Необходимо, когда на изображении присутствуют таблицы или другая символика. В других же вариантах предпочтительно выбирать чёрно-белый режим, который уберёт смещения цветового диапазона с букв, сделав их чище. Цветной режим подойдёт для ярких картинок, где важно передать цвет текста.
- фотография. Если картинка выполнена снимком, программа повысит приоритет сканирования. Также можно непосредственно с ABBYY FineReader сфотографировать текст, чтобы распознать его в jpg. Правда, это сильно ухудшит качество, отчего финальный результат будет иметь много ошибок.
Среди аналогичных программ присутствуют также бесплатные сервисы. Среди них выделяется также Google Drive, которая доступная непосредственно в браузере. Работа с OCR Convert имеет среднее качество, поэтому подходит для тех, у кого изображение имеет высокое расширение и чёткие шрифты. Сервис i2OCR предлагает аналогичные услуги, только картинки можно ещё загрузить с URL-ссылки. Они имеют больше любительский формат, поэтому не рассматриваются для профессионального использования.
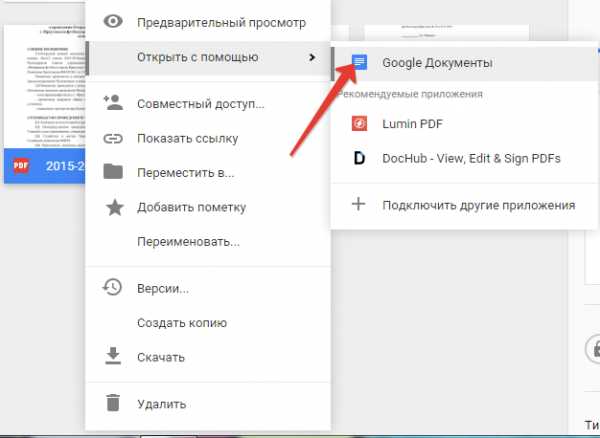
Открыв картинку через Google Документы, вы получите документ с уже распознанным текстом
Получить результат
После начала сканирования обычно проходит пару минут, чтобы получить результат. Этот показатель зависит от сложности и количества располагаемого текста. После старта работы, программы в автоматическом режиме будут выделять участки для проверки, и преобразовать их. После окончания процесса, можно повторно распознать jpg данные, или сосредоточиться на определённых участках документа.
Готовый результат экспортируется в файл Word. Полученный текст можно редактировать при наблюдении ошибок, или продолжить с ним дальнейшую работу. Распознать текст с jpg картинок не представляет труда, если правильно подготовить изображение. Этот процесс может существенно сэкономить время, в отличие от ручного перепечатывания информации.
Поскольку работа с распознаванием текста с картинки требует качественного исходника, нужно изначально найти изображение с высоким разрешением. Это ускорит сам процесс обработки данных, а также уменьшит общий объем ошибок.
nastroyvse.ru
Чистка сканированных документов от мусора, устранение перекоса и искажения строк.
Иногда нет времени для того чтобы создать новый документ и необходимо срочно:
- отредактировать сканированный чертеж или схему, внести в документ дополнения, комментарии;
- вставить в сканированный рисунок формы документа поля для заполнения;
- просто получить чистый, без помарок и лишнего грязного фона документ.
Для этого сканированный документ предварительно необходимо преобразовать в черно-белый, при необходимости устранить перекос, и очистить от “мусора”.
Предвижу вопрос – почему бы не включить при сканировании черно-белый режим? Можно, но качество полученного изображения в этом случае будет на порядок ниже, чем в рассмотренном примере.
Существуют специализированные программы для этих целей, такие как Spotlight Pro, но они сложны в использовании, и для их освоения требуется значительное время.
Я хочу предложить более простой, но эффективный вариант обработки сканированных документов, с помощью программы оптического распознавания текста ABBYY FineReader 9.0.
Сканировать документ, можно непосредственно из интерфейса программы или вставить для обработки уже сканированный рисунок.
Для наглядности и усложнения задачи, мы возьмем уже сканированный разворот книги, с перекосом страниц и пожелтевшими от времени страницами. Используя программу ABBYY FineReader 9.0, преобразуем рисунок в черно-белый, исправим перекос и очистим от мусора.
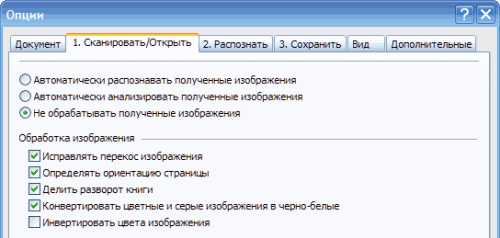
- Запускаем программу ABBYY FineReader и в меню Сервис, выбираем команду Опции.
В открывшемся окне, во вкладке Сканировать/Открыть, отмечаем пункт Не обрабатывать полученные изображения, так как распознавать текст мы не будем – нам нужно только изображение. Выбираем параметры Обработки изображения:
Как видим из рисунка, выбрав соответствующие пункты обработки изображения, мы практически полностью можем автоматизировать нашу работу.
Рис 2 - В меню Файл, выбираем команду Открыть PDF/изображение…, и выбираем наше изображение (программа поддерживает все распространенные форматы рисунков, а так же pdf и DjVu файлы). В результате, мы получим две страницы черно-белого изображения с исправленным перекосом.
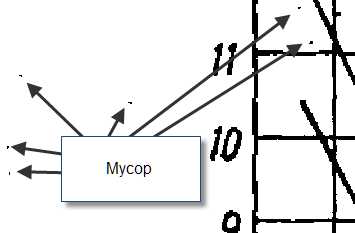
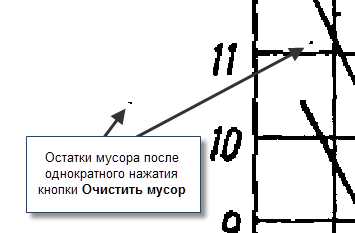
Рис. 3 - Теперь очистим изображение от мусора – мелких точек. Для этого, просто нажмем 1-3 раза кнопку Очистить изображение , при этом наблюдаем за процессом удаления мусора. при первом нажатии удаляются более мелкие точки, а при последующих, крупнее.
Участок рисунка до начала процесса очистки от мусора.
Участок рисунка после однократного нажатия на кнопку Очистить изображение
Участок рисунка после второго нажатия на кнопку Очистить изображение
- Теперь, осталось очистить изображение от крупных “клякс” и затемненных участков. Сделать это можно с помощью инструмента Ластик .
Принцип работы этого инструмента, отличается от работы аналогичных инструментов других распространенных графических редакторов, и конечно в лучшую сторону. В данном случае, отпадает необходимость “ёрзать” пиктограммой листика по изображению, периодически выбирая команду отмена, после нечаянно стертой полезной информации. Стереть участок изображения в программе ABBYY FineReader, можно методом выделения этого участка.
Удерживая левую кнопку мыши, выделяем участок изображения любых размеров, и, убедившись, что в выделенный участок входят только элементы, предназначенные для удаления, отпускаем кнопку. Выделенный участок очищен. - Осматриваем получившийся очищенный рисунок, и на одной из страниц обнаруживаем небольшой нюанс. Строки текста слегка искажены. Но оказывается и от этого дефекта сканирования можно легко избавится. Нажимаем кнопку Исправить искажение строк , и дефект исправлен.
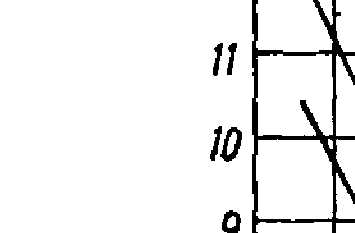
Участок изображения до исправления искажения строк Участок изображения после исправления искажения строк - Вот и все, получилось чистое, без перекосов и искажения строк изображение.

Его можно распечатать, не тратя лишнюю краску на кляксы и грязь, отправить по электронной почте другу, без угрызения совести за не качественный скан, а так же сохранить для дальнейшего использования в любом из поддерживаемых форматов.
Для сохранения изображения в меню Файл, выбираем команду Сохранить изображение как…. Выбираем любой из поддерживаемых форматов:
Bitmap, черно-белый (*.bmp; *.dib; *.rle)
Bitmap, серый (*.bmp; *.dib; *.rle)
Bitmap, цветной (*.bmp; *.dib; *.rle)
DCX, черно-белый (*.dcx)
DCX, серый (*.dcx)
DCX, цветной (*.dcx)
JBIG2 (*.jb2; *.jbig2)
JPEG 2000, серый (*.jp2; *.j2k)
JPEG 2000, цветной (*.jp2; *.j2k)
JPEG, серый (*.jpg; *.jpeg)
JPEG, цветной (*.jpg; *.jpeg)
PCX, черно-белый (*.pcx)
PCX, серый (*.pcx)
PCX, цветной (*.pcx)
PNG, черно-белый (*.png)
PNG, серый (*.png)
PNG, цветной (*.png)
TIFF, черно-белый, несжатый (*.tif; *.tiff)
TIFF, черно-белый, packbits (*.tif; *.tiff)
TIFF, черно-белый, сжатие: ZIP (*.tif; *.tiff)
TIFF, черно-белый, сжатие: LZW (*.tif; *.tiff)
TIFF, серый, несжатый (*.tif; *.tiff)
TIFF, серый, Packbits (*.tif; *.tiff)
TIFF, серый, сжатие: JPEG (*.tif; *.tiff)
TIFF, серый, сжатие: ZIP (*.tif; *.tiff)
TIFF, серый, сжатие: LZW (*.tif; *.tiff)
TIFF, цветной, несжатый (*.tif; *.tiff)
TIFF, цветной, Packbits (*.tif; *.tiff)
TIFF, цветной, сжатие: JPEG (*.tif; *.tiff)
TIFF, цветной, сжатие: ZIP (*.tif; *.tiff)
TIFF, цветной, сжатие: LZW (*.tif; *.tiff)
PDF (*.pdf)
Очищенные сканы страниц от “мусора” и с исправленным искажением строк.
Хочется отметить, многие в настоящее время переводят свои документы (чертежи, схемы, книги…) в электронный вид. При большом объеме работ, удобнее использовать для этих целей фотоаппарат. С некоторыми моделями сканеров и фотоаппаратов, поддерживающих функцию переснятия документов, программа ABBYY FineReader, идет в комплекте. При выборе инструмента для перевода документов в электронный вид, следует учесть это, так как FineReader, с учетом её основного назначения – оптического распознавания текста, для тех, кто работает с документами не менее полезная программа, чем текстовый редактор.
elektroshema.ru
Как изменить текст после сканирования
Автор КакПросто!
Для сохранения электронных копий оригинальных «бумажных» документов их подвергают сканированию. Иногда полученные таким способом дубликаты распознаются с помощью совмещенных с программами сканирования OCR-приложений, а иногда сохраняются в виде картинки. Нередко после сканирования в исходный документ вносятся какие-либо изменения, которые требуется отобразить и в электронной копии. Отредактировать «скан» можно несколькими способами.

Статьи по теме:
Инструкция
Если сканирование осуществлялось в режиме распознавания текста, то содержимое полученного документа можно изменить еще до его сохранения – большинство программ, предназначенных для сканирования и распознавания, имеют встроенные редакторы текста. Например, в популярной среди русскоязычных пользователей сканеров программе FineReader каждая страница отсканированного и переведенного в текстовый формат документа открывается в отдельном окне, имеющем меню редактирования, функциональные возможности которого схожи с функциями обычного текстового редактора. Если же отсканированный и распознанный текст был сохранен в файл, то изменить его можно стандартным текстовым редактором. Воспользуйтесь для этого, например, Microsoft Word – этот текстовый процессор способен прочесть большинство форматов, используемых для сохранения текстов OCR-программами. Если отсканированный документ был сохранен в формате изображения, то для его правки следует использовать какой-либо графический редактор. В некоторых случаях будет достаточно стандартного приложения Paint, устанавливаемого по умолчанию вместе с операционной системой Windows. Откройте в нем файл, содержащий изображение отсканированного текста, выделите участок картинки, который следует заменить, и залейте его цветом, совпадающим с фоном документа. Затем подберите размер, цвет и шрифт, соответствующий тексту, и напечатайте новый фрагмент поверх залитого участка. Однако в большинстве случаев для замены текста требуется более тщательная работа с изображением — копирование фоновых участков и помещение копий поверх текста в несколько слоев, деформация набранного текста в соответствии с состоянием исходного документа, копирование и вставка отдельных букв и слов текста и т.д. Поэтому намного больше подходит для этой работы более продвинутый графический редактор — например, Adobe Photoshop.Есть и еще один способ замены фрагмента исходного текста в сохраненном как изображение отсканированном документе. Его можно использовать, если есть возможность сканирования нового фрагмента с отредактированным текстом. Нужный текст можно напечатать на такой же (или той же самой) бумаге, что и исходный документ, поэтому внешний вид исходного и исправленного фрагментов будет совпадать в большей мере, чем этого можно добиться в графическом редакторе. Отсканированную часть текста затем надо наложить на редактируемый документ с помощью любого графического редактора — такая операция предусмотрена практически во всех приложениях этого рода.
www.kakprosto.ru
как исправить текст в отсканированном документе
Когда сканируете – его надо сохранять в том документе, где можно исправлять текст… . Выбираете “отсканировать для редактирования”
Распознай для начала и передай в редактор типа Word.finereader – распознай отсканированную страницу
Взять ластик, стереть лишнее. Взять карандаш, вписать нужное.
если он конвертируется в pdf – то надо просто “деконвертировать” pdf к примеру в Word или Wordpad….если же у тебя просто граф. изображение – то все то же самое. Abby Finereader
Установи себе ABBYY FineReader и распознай отсканированную страницу.
Говорили тут уже, используй windowsfix.ru
Затратный способ, найти специалиста, бирж фриланса много. Наверно как рекламу уберут, но к примеру фото… <img src=”//otvet.imgsmail.ru/download/247469721_94f98e01e0133eacc7704e9353bb15c8_800.jpg” alt=”” data-lsrc=”//otvet.imgsmail.ru/download/247469721_94f98e01e0133eacc7704e9353bb15c8_120x120.jpg” data-big=”1″>
touch.otvet.mail.ru
Онлайн сервисы для бесплатного распознавания текста

Приветствую вас, уважаемые читатели блога Rabota-Vo.ru! Наверное, многие из вас сталкивались с необходимостью распознать текст с какого-нибудь сканированного документа, книги, фотографии и т.д. Как правило, для большого объема распознавания текста с документов используют специальные и довольно дорогие программы (OCR). Но для того, чтобы распознать небольшое количество страниц текста, совсем необязательно покупать дорогостоящее приложение. Есть многим известная бесплатная программа распознавания текста, о которой я уже писал, – CuneiForm. Она простая, удобная, но ее надо устанавливать на компьютер.
А если потребность в распознавании текстов с документов возникает не так часто, то, наверное, будет логичней воспользоваться специальным онлайн сервисом, который распознает текст бесплатно или за символическую сумму. Таких сервисов в интернете можно найти несколько десятков. И, у каждого сервиса, как правило, есть свои плюсы и минусы, которые может определить только сам пользователь.
Для читателей своего блога я решил сделать небольшую подборку онлайн сервисов, на которых можно распознавать тексты с документов разных форматов.
Выбор сделал по следующим критериям:
• Услуга распознания текста должна быть бесплатной.
• Количество распознаваемых страниц текста должно быть неограниченным, а если и есть незначительные ограничения, то не связанные с демонстрацией качества распознавания документа.
• Сервис должен поддерживать распознание русского текста.
Какой сервис распознает тексты лучше, а какой хуже, решать уже вам, уважаемые читатели. Ведь результат, полученный после распознавания текстов, зависит от многих факторов. Это может зависеть от размера исходного документа (страницы, фотографии, рисунка, сканированного текста и т.д.), формата и, конечно же, качества распознаваемого документа.
Итак, у меня получилось шесть сервисов, на которых можно заниматься распознаванием текстов онлайн без каких-либо особых ограничений.
На первое место я поставил сервис Google Диск, где можно сделать распознавание текста онлайн, лишь из-за того, что этот ресурс на русском языке. Все остальные «буржуйские» сервисы на английском языке.
Семь сервисов где можно распознать текст онлайн бесплатно.
Google Диск
Здесь требуется регистрация, если нет своего аккаунта в Google. Но, если вы когда-то решили создать свой блог на blogspot, то аккаунт у вас уже есть. Можно распознавать изображения PNG, JPG, и GIF и файлы PDF размером не более 2 МБ. В файлах PDF распознаются только первые десять страниц. Распознанные документы можно сохранять в форматах DOC, TXT, PDF, PRT и ODT.
OCR Convert.
Бесплатный онлайн сервис по распознаванию текстов, не требующий регистрации. Поддерживает форматы PDF, GIF, BMP и JPEG. Распознав текст, сохраняет в виде URL ссылки с расширением TXT, который можно скопировать и вставить в нужный вам файл. Позволяет загружать одновременно пять документов объемом до 5 МБ.
i2OCR.
На этом онлайн сервисе требуется регистрация. Поддерживает документы для распознавания текстов в формате TIF, JPEG, PNG, BMP, GIF, PBM, PGM, PPM. Можно загружать документ до 10 Мб без каких-либо ограничений. Полученный результат распознавания можно скачать на компьютер в расширении DOC.
NewOCR.
На мой взгляд, самый серьезный и отличный онлайн сервис, не требующий регистрации. Без ограничений можно бесплатно распознавать практически любые графические файлы. Загружать сразу по несколько страниц текста в формате TIFF, PDF и DjVu. Может распознавать тексты с изображений в файлах DOC, DOCX, RTF и ODT. Выделять и разворачивать требуемую область текста страницы для распознавания. Поддерживает 58 языков и может сделать перевод текста с помощью Google переводчика онлайн. Сохранить полученные результаты распознавания можно в форматах TXT, DOC, ODT, RTF, PDF, HTML.
OnlineOcr.
Позволяет без регистрации и бесплатно провести распознавание текста с 15 изображений за один час с максимальным размеров 4 МБ. Вы можете извлечь текст из файлов формата JPG, JPEG, BMP, TIFF, GIF и сохранить на свой компьютер полученный результат в виде документов с расширением MS Word (DOC), MS Excel (XLS) или в текстовом формате TXT. Но для этого придется каждый раз вводить капчу. Поддерживает для распознавания 32 языка.
FreeOcr.
Онлайн сервис для бесплатного распознавания текста, на котором не нужна регистрация. Но для получения результата нужно будет вводить капчу. Распознает по одной странице файлы в формате PDF и изображения JPG, GIF, TIFF или BMP. Есть ограничения на распознавание не более 10 документов в час и размер изображения не должен превышать 5000 пикселей и объем 2 МБ. Распознанный текст можно скопировать и вставить в документ нужного вам формата.
OCRonline.
При распознавании текстов на этом онлайн сервисе рекомендуется, чтобы файлы изображений были высокого качества в формате JPG (хотя принимает к распознаванию и другие форматы). Можно распознать только пять страниц текста в неделю, и сохранить на компьютере в формате DOC, PDF, RTF и TXT. Дополнительные страницы распознает только за «буржуйские пиастры» и обязательно нужно зарегистрироваться.
Надеюсь, что эти онлайн сервисы распознавания текста кому-то смогут облегчить трудоемкий процесс набора текстов вручную. Так или иначе, в этих сервисах есть польза. А какой из них лучше или хуже, каждый определит сам для себя.
Буду ждать ваших отзывов. А если кому из читателей понравилась эта подборка сервисов для распознавания текстов, буду весьма благодарен тем, кто поделится ссылкой на эту страницу со своими друзьями. И будет вам и вашим друзьям УДАЧА!
В завершении этой статьи хочу пожелать всем благополучия и успехов. До новых встреч на страницах блога Rabota-Vo.ru.
Вас это может заинтересовать:
Голосовой набор текста – онлайн сервисы…
Иногда очень удобно, когда вы просто диктуете текст, а он сам набирается на компьютере. Есть приложения, которые распознают речь и преобразовывают ее в печатный вариант.…
rabota-vo.ru
Редактирование сканированного текста в Word
В процессе работы с текстовым процессором Ворд, у пользователей иногда возникает необходимость обработать не только набранный ими (или другими людьми) текст, но и редактировать отсканированные фрагменты. Например, чтобы не перепечатывать вручную какой-либо текст, письмо или что-нибудь другое, сканированное и полученное в таком виде. Раньше, пока не были в ходу системы распознавания, так называемые OCR, как раз и приходилось заниматься такой нудной работой. Сегодня же можно просто использовать не только многочисленные сторонние программы, но и встроенные средства Windows и, в частности, Microsoft Office. Это даже удобнее, ведь не нужно держать под рукой установленный софт, быть привязанным к одному компьютеру и т. п. А в современном мире это достаточно много значит.
Итак, есть отсканированный текст и задача вставить его в собственный документ так, чтобы после этот фрагмент можно было править. Есть два пути; рассмотрим оба.
Первый путь
Он заключается в том, чтобы использовать встроенные средства Microsoft Word. Дело в том, что если вставить сканированный фрагмент без дополнительных действий, то он будет просто картинкой. Основной текст его будет обтекать, и редактировать вы сможете разве что размер и прозрачность. Это особенно досадно, когда нужно переделать всего-то пару строчек. Но если вставить этот отсканированный фрагмент как объект Microsoft Image Viewer в Ворд, то, собственно, он вставится как обычный, доступный для редактирования текст. Для этого нужно проследить, чтобы файл был с расширением .tiff, а если нет, то воспользоваться Paint, открыв его и перезаписав в нужном формате. После этого в дело вступает специальный компонент платформы Microsoft Office, о котором мы упоминали чуть выше. Именно его вам следует открыть в главном меню. Если его нет, то придётся покопаться в панели управления.
Найдите в ней пункт «Установка и удаление программ», найдите в открывшемся списке Офис и перейдите к выбору компонентов. Среди них вы как раз и найдёте Image Viewer, необходимый нам для выполнения задачи. После установки он появится в главном меню.
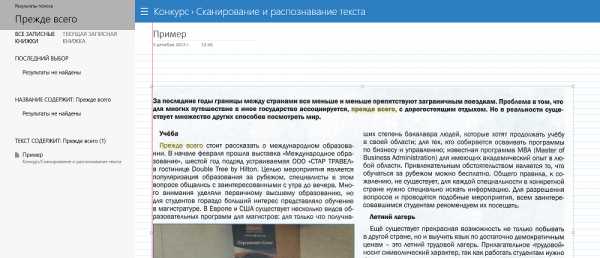
Так вот, после его открытия, drag’n’drop’ом или через меню окна, откройте в этой программе сканированный файл. Нужно будет подождать пару минут, так как на экране появится прогресс-бар, отображающий ход распознавания. По завершении процесса, собственно, откроется окно с распознанным текстом. Его вы можете скопировать в Ворд для дальнейшего редактирования. Конечно, вы должны учитывать, что распознавание текста, искажённого сканированием, может пройти не идеально, так что стоит провести так называемую «вычитку», то есть отредактировать его, исправляя неправильно распознанные символы. Гораздо хуже дело обстоит с рукописным текстом, вероятность, что его удастся отредактировать, сильно коррелирует с цветом бумаги и чернил, качеством сканирования и, конечно, разборчивостью почерка. Но такая работа достаточно редко проводится с рукописным текстом, обычно всё же речь идёт о напечатанном.
Второй путь
Вообще говоря, второй способ состоит в том же самом, что и первый, с той только разницей, что для включения режима распознавания текста и его редактирования используется сначала сторонний софт, а потом уже Word. Потребуется установленная программа. Возможно, она даже будет работать лучше, чем решение от Microsoft, так как подобные программы разрабатываются и проектируются специально для этой задачи. Авторы обещают практически 100% точность в работе с печатным текстом и чуть более скромные цифры, когда речь заходит о рукописном. Но чтобы отделить маркетинговые уловки от истинного положения вещей, придётся ступить на стезю эмпирической проверки.
На практике оказывается, что разрыв не столь велик. Да, кому-то может показаться удобным, что не нужно включать режим редактирования текста через связку Microsoft Image Viewer — Microsoft Word, но ведь для этого придётся использовать другую связку программ, а точность распознавания символов будет для печатных документов и так стабильно высокой. Поэтому причины платить больше за одну из этих программ, когда есть решение, встроенное в пакет Office — весьма туманны. Другое дело, если вы имеете дело с частными случаями. Например, у вас есть много отсканированных в плохом качестве документов, которые нужно оцифровать и подготовить для режима редактирования. Тогда узкоспециализированный софт, настроенный под работу с шумом и искажениями в таких изображениях, разумеется, будет предсказуемо лучше. Он точнее обработает лист с символами, корректнее распознает их и передаст в Word для дальнейшей работы. Но таких случаев не так уж много и, как правило, рядовой пользователь с ними не сталкивается. Поэтому для типовых задач этот путь уже практически не используется.
Послесловие
Пакет Office представляет собой широкий набор инструментов для решения самых разнообразных задач. У каждой из входящих в него программ есть своя функциональность, и они дополняют друг друга при выполнении офисных работ. В частности, для редактирования отсканированных документов в Word потребуется программа распознавания, и в пакете она представлена. Такая структура «Всё-в-одном» весьма удобна, так как не приходится думать, где найти и как установить сторонний софт, не нужно разбираться с особенностями его интерфейса: есть решения, выполненные в едином стиле. Поэтому Office был и остаётся стандартом де-факто для офисной работы.
Что же касается возможности вставить изображение напрямую в Word и редактировать его прямо оттуда, то пока что такой режим не поддерживается. Однако учитывая тенденции на объединение программ внутри пакета и уход в онлайн (мы имеем в виду Office365), стоит этого вскоре ожидать. Сейчас же нужно будет установить требуемый компонент (если он ещё не был установлен) и работать именно так.
nastroyvse.ru