Бесплатные программы распознавание текста – Лучшие программы и онлайн сервисы для распознавания текста с картинки или фото
- Комментариев к записи Бесплатные программы распознавание текста – Лучшие программы и онлайн сервисы для распознавания текста с картинки или фото нет
- Советы абитуриенту
Лучшие бесплатные программы для сканирования и распознавания текста
Существуют специальные программы, которые умеют «читать» изображения с текстом. Конвертация заключается в том, что на основе алгоритма текст, изображенный на отсканированном документе, преобразовывается в предложения. Вся сложность в том, что на картинке программа видит не набор букв, а растр, точечную структуру. Все эти точки, имеющую различную форму, расшифровываются специальными утилитами, превращая его в обыкновенный текст, с которым можно в дальнейшем работать.Программы распознавания текста применяются при переводе различной бумажной литературы и документов в электронный вид. Библиотеки и архивы таким же образом переводятся в цифровой вид.
Автоматическая оцифровка с помощью программы выигрывает у ручного метода набора в скорости, поэтому этот метод так распространен. Мы расскажем вам о пяти лучших программах распознавания сфотографированных текстов.
ABBYY FineReader 10
FineReader — флагман среди программного обеспечения, распознающего тексты на картинках. Эта программа широко распространена среди обычных пользователей и профессионалов, занимающихся оцифровками. Популярность обусловлена качеством ее работы. FineReader отлично обрабатывает кириллицу и еще 178 языков.
Единственный недостаток программы, если можно так выразиться, ее платность. Но пользователи, опробовавшие ее работу в течение двух недель и отсканировавшие ряд страниц, покупают продукт, поскольку он, однозначно, стоит своих денег.
FineReader умеет «считывать» текст с любых изображений, причем не самого высокого качества. С помощью программы вы переведете в цифровой вид любой документ: от обычного изображения до сканированной страницы.
Плюсы:
- Четко распознает текст;
- Читает множество языков;
- Не предъявляет больших требований к качеству картинки, документа, фото.
- Бесплатная версия ограничена временем (две недели) и количеством отсканированных страниц (55).
OCR CuneiForm
CuneiForm оптически распознает тексты на графических файлах и приводит их в редактируемый вид. Утилита выпускается в одной версии, бесплатной, и отличается от предыдущей программы качеством распознавания. Но это не смущает, и многие используют бесплатный софт, считая, что его функциональные возможности отлично справляются с работой.
Любопытная информация! CuneiForm умеет читать не только графику с текстом, но и разнообразные таблицы. И в том числе, если таблицы идут сплошным текстом, без разлиновки.
С помощью этой программы вы не только переведете текст в цифровой вид, но и сохраните шрифт и размер высоты букв. База шрифтов CuneiForm обширна, утилита даже умеет распознавать отсканированные, отпечатанные на машинке, изображения.
Для более четкой расшифровки текста в утилите используются специализированные словари. Эти словари постоянно пополняются, поэтому у CuneiForm богатый запас слов.
Плюсы:
- Бесплатная версия программы;
- Текст корректируется для точности с помощью словарей;
- Расшифровывает любые изображения, даже некачественные;
- Сохраняет структуру документа, даже его форматирование.
- Погрешности в текстах;
- Поддерживается всего 24 языка.
WinScan2PDF

WinScan2PDF — компактная утилита, сканирующая любые документы. Она выпускается в виде переносимого файла, portable-версии, которую не надо устанавливать на компьютер и прочие устройства. Утилита мгновенно читает любой текст и сохраняет его только в PDF-документ.
Программой очень легко пользоваться даже самым неподготовленным пользователям. Чтобы получить необходимый результат, вам придется нажать всего лишь три кнопки:
- Выбрать графический файл;
- Указать место загрузки;
- Запустить процесс.
Плюсы:
- Отсутствие дистрибутива;
- Мгновенная расшифровка текстовой графики;
- Минималистский, удобный интерфейс.
- Вес утилиты всего 55 Kb;
- Текст можно сохранить только в формате переносимого документа.
SimpleOCR
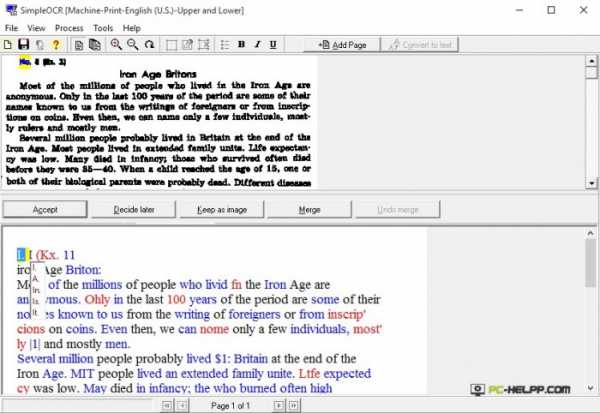
SimpleOCR — бесплатное приложение, распознающее отсканированный текст оптически, но только на иностранных языках. Русского языка, к сожалению, нет ни в пакете интерфейса, ни в списке поддержки. А в остальном утилита отлично справляется с работой, распознавая даже рукописные тексты.
Тексты, получаемые на выходе, отличаются высоким уровнем точности. Также с помощью утилиты можно извлечь графический файл и удалить шум. Еще одной отличительной особенностью является наличие встроенного редактора текста, что очень удобно в использовании.
Плюсы:
- Работает корректно, с высокой точностью;
- Умеет удалять шумы с графики;
- Позволяет сразу редактировать полученные тексты.
- Отсутствует русскоязычная поддержка.
Freemore OCR
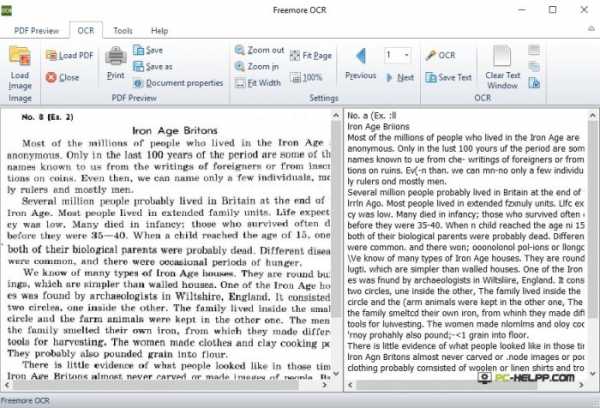
Freemore
В интерфейсе нет поддержки русского языка, но даже, несмотря на это, утилита распространена и популярна среди отечественных пользователей, поскольку очень проста в использовании.
Плюсы:
- бесплатная версия;
- шифрует и дешифрует файлы;
- позволяет просматривать свойства документа;
- простой, не перегруженный кнопками, интерфейс;
- корректный, высокой точности результат на выходе;
- читает сразу несколько сканеров.
- Пользовательский интерфейс не переведен на русский язык;
- Для расшифровки русских текстов необходимо загрузить дополнительно язык.
pc-helpp.com
Распознавание текста | Программы для Windows 7, 8, 10
Мы отобрали лучшие приложения, выпущенные разработчиками в помощь тем, кто часто имеет дело с бумажными документами или их отсканированными копиями. Вы можете скачать любую представленную у нас программу для распознавания бесплатно.
Чтобы получить возможность редактировать отсканированный или сфотографированный текст, его нужно распознать. Делается это с помощью специальных программ для распознавания текста, которые мы и поместили в эту категорию.
Большинство из них работают с английским, русским и другими распространенными языками, позволяют сохранять шрифт и структуру оригинала, а также поддерживают экспорт файлов в текстовые редакторы. Приложения отличаются функционалом, интерфейсом и скоростью работы. Поэтому прежде, чем установить выбранный софт, внимательно прочитайте обзоры, сравните преимущества и недостатки.
ABBYY FineReader 12 — программа для мгновенного распознавания текста из цифровых изображений и любых типов PDF-файлов с возможностью преобразования результатов в наиболее популярные электронные форматы.
Punto Switcher — бесплатный модуль, обеспечивающий своевременные переключения между раскладками клавиатуры на компьютере пользователя.
VueScan — условно-бесплатная программа, способная существенно расширить диапазон возможностей Вашего сканера.
OCR CuneiForm — бесплатное русскоязычное приложение, позволяющее распознавать текст на изображениях или отсканированных документах.
www.freeversions.ru
Бесплатная программа для распознавания текста FreeOCR, не дружит с русским языком
До недавнего времени был уверен, не существует бесплатных программ для распознавания отсканировано текста, когда надо документы, книги пригнать на компьютер. Есть только монстры, вроде, популярного у нас ABBYY FineReader, за который в обязательном порядке придется выкладывать немаленькие деньги. Но, оказалось, есть бесплатные OCR (оптическое распознавание символов) программы, развитие которых поддерживают энтузиасты. Среди таких представителей, абсолютно бесплатное приложение для распознавания текста FreeOCR.
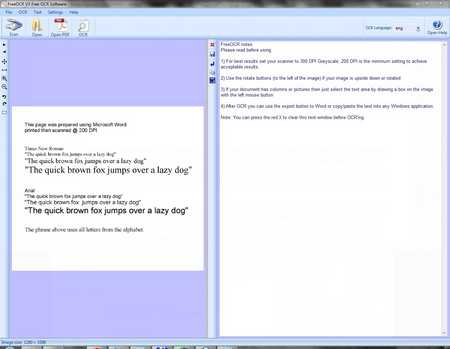
Обязательно проверьте пред началом установки, чтоб компьютер был подключен к интернету, потому-то будем запускать оболочку, которая будет скачивать все необходимые файлы, ведь установочный файл весит всего 150 кб, и туда точно невозможно поместить все необходимое для работы столь сложной программы . Разработчики предупреждают, что будут скачано дополнительно 11 мегабайт, в моем случае папка с установленной программой весит 4 Мб. В остальном стандартный перечень вопросов, в какую папку ставить и подтверждение лицензионного соглашения.
Запустив программу, неожиданно получаем простенький, но вполне современный интерфейс. Даже хотел сказать, что там есть ленточное меню, но его там нет, просто разработчикам удалось все настолько стильно и органично сделать.
FreeOCR может распознавать текст с документов, полученных из pdf файлов (работает с ними довольно медленно и тормознуто, когда перелистываешь страницы), графических фалов (поддерживаются все основные форматы) и со сканера (жмем на кнопку, выбираем один из доступных сканеров, а дальше все на автомате, никаких настроек не предлагается). Собственно этому и посвящено меню с большими иконками, под основным, которые красноречиво расскажут о своем назначении. Кто задается вопросом, зачем нужна кнопка «OSR», собственно поле нажатия на неё и происходит распознавание текста.
Все окно программы разделено на две половины, в левой стороне находится каретника с текстом которое надо распознать, а с правой, текст, результат работы программы.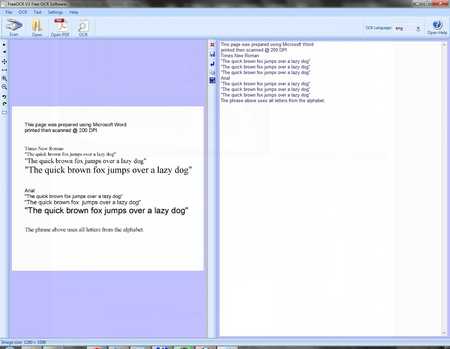
Теперь надо рассказать о некоторых нюансах работы FreeOCR. Программа не может автоматически разбивать страницу на колонки, или определить где именно находятся картинки, поэтому для получения нормальных результатов, ту часть изображения, которую надо распознать необходимо, выделить, зажав правую кнопку мыши. На боковой панели есть несколько кнопок, которые позволяют облегчить с картинками, это зум, вращение на 90 градусов (когда текст лежит боком), и перелистывание многостраничных документов.
Весь текст, который распознал FreeOCR, добавляется к уже существующему в самый конец, поэтому желательно каждый раз очищать это окно, чтоб не приходилось искать какие абзацы были переведены. Панель иконок помогает работать с текстом, позволяет быстро стирать текст в правой панели, сохранять в готовый текст в файл, копировать в буфер обмена, убирать разметку страницы и отправлять в текстовый редактор Word (почему именно ему досталась такая честь непонятно).
Только вот с языками вышла заминка, с текстом на английском языке справляется неплохо, но вместо рисских слов выдает нечитаемый набор символов. Как оказалась, какой язык надо использовать при распознавании текста, выбираем вручную из выпадающего меню справа вверху, оно подписано «OSR Language». По умолчанию идет только английский, остальные придется добавлять отдельно.
Для начала оправляемся по ссылке http://code.google.com/p/tesseract-ocr/downloads/list, находим нужный нам язык, среди кучи фалов и скачиваем себе на компьютер. Распаковываем архив, приходим в программе в раздел меню «Settings->Open Language Folder», и в открывшуюся папку перетаскиваем файлы из архива. Перезапускаем и новый язык добавлен в выпадающее меню FreeOCR.
Только вот у меня даже после добавления русского языка, программа упорно не хочет понимать это язык, показывая, что начался процесс обработки, но без результатов, остается пустое место, не распознавания текста, хотя с английским работает прекрасно. Пока как с этим бороться не ясно, буду экспериментировать и если найду рецепт лечения, расскажу его.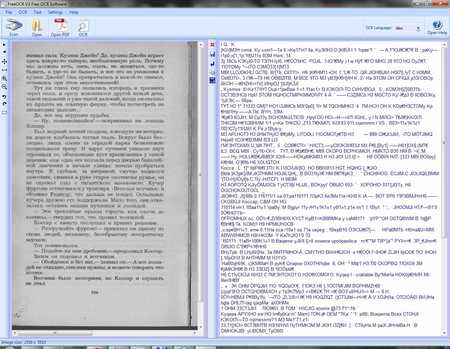
Как оказалось движок Tesseract OSR (что это такое, написано ниже) который здесь используется для распознавания текста старой версии 2.04, сейчас актуальный 3.0, и в нем поддержки русского языка, только английский, немецкий, испанский, итальянский, французский и еще несколько экзотических. В общем, при всей своей перспективности, программа в нынешнем виде абсолютно бесполезна в нашей стране, пока не начнет использовать Tesseract OSR 3.0, а там нормально поддерживается русский язык. Вот именно для этой версии готова поддержка распознавания текста большого количества языков.
Настроек в программе нет, все работает в автоматическом режиме.
Теперь хочу немного рассказать, откуда появился FreeOCR. Как оказалось движок, который распознает текст, взят из открытого проекта под названием Tesseract OSR. Разработчики FreeOCR только сделали свою оболочку и все максимально автоматизировали, чтоб не дергать пользователей лишними вопросами.
При всем пессимизме пред началом работы FreeOCR, он действительно работает и оказался очень дружелюбный к пользователям. Во всем можно разобраться в течение нескольких минут. Но это касается только английского языка, который идет по умолчанию, добавление поддержку других языков, можно охарактеризовать моя борьба.
Еще есть достаточно серьезные недостатки, это не уверенное распознавание символов, слишком много возникает ошибок, потом приходиться тратить время на проверку правописания и все перечитывать. Но сама главное это поддержка малого количества языков, русский не входит в список избранных. В нынешнем состоянии не рекомендую использовать. Хотя кто работает с документами на английском языке, может стать неплохим выбором, ведь можно бесплатно использовать даже в коммерческих организациях.
Прекрасно работает в 32-х и 64-х битных операционных системах. Интерфейс программы только на английском языке, но пунктов и надписей немного поэтому не составит труда разобраться.
Официальный сайт FreeOCR http://www.paperfile.net/
Сайт для бесплатного скачивания FreeOCR http://www.paperfile.net/
Последняя версия на момент написания FreeOCR 3.0
Размер программы: установочный файл 156 Кб
Совместимость: Windows Vista и 7, Windows Xp
OCR CuneiForm программа для распознавания сканированного текста
| Название: | OCR CuneiForm |
| Версия: | V.12 |
| Язык интерфейса: | Русский |
| Размер: | 33,4Mb |
| Лицензия: | Бесплатная |
| Сайт разработчика: | http://www.cuneiform.ru/ |
Как отредактировать сканированный текст или вставить часть сканированного текста в тестовый редактор?
С этим легко справиться OCR CuneiForm.
OCR CuneiForm это бесплатная программа для распознавания текста, которая распознает сканированный текст и импортирует его в текстовые редакторы.
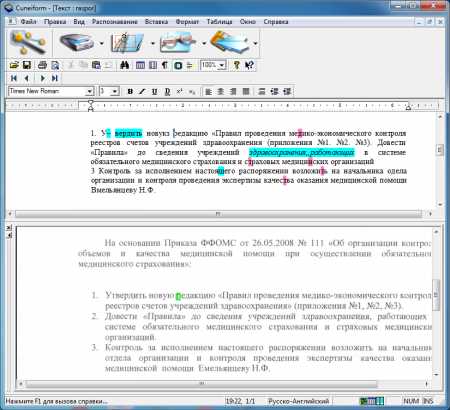
Иногда нам надо сделать реферат или просто отредактировать или скопировать часть текста одной из книг или журнала, а данной книги нет в электронном виде, а набирать много текста вам просто некогда и неудобно, вот тогда, возникает вопрос, как перенести текст из книги в текстовый редактор. Все что нам нужно это сканировать текст и перевести его в электронный вид.
Для начала сканируем нужный текст из требуемой нам литературы, выбираем наш файл, запускаем распознавание текста сохранить документ в предлагаемом формате текстового редактора, после Вы можете удалить, добавить свой текст, вырезать и вставить его в свой реферат.
Читать статью о программах для распознавания текста.
softfly.ru