Текст из pdf – Преобразовать PDF в текстовый файл — Конвертируйте PDF в текстовый файл онлайн
- Комментариев к записи Текст из pdf – Преобразовать PDF в текстовый файл — Конвертируйте PDF в текстовый файл онлайн нет
- Советы абитуриенту
text – Как извлечь текст из PDF?
С сегодняшнего дня я это знаю: лучшая вещь для извлечения текста из PDF файлов TET, инструмент для извлечения текста. TET является частью семейства продуктов PDFlib.com.
PDFlib.com – компания Томаса Мерца. Если вы не узнаете его имя: Томас Мерц является автором “Библии PostScript и PDF”.
Первая инкарнация TET библиотека. Вероятно, это может сделать все, что хотел Budda006, включая позиционную информацию обо всех элементах на странице. О, и он также может извлекать изображения. Он рекомбинирует изображения, фрагментированные на куски.
pdflib.com также предлагает другое воплощение этой технологии, плагин TET для Acrobat. Третьим воплощением является PDFlib TET iFilter. Это автономный инструмент для пользовательских настольных компьютеров. Оба они бесплатны (как в пиве) для использования в частных некоммерческих целях.
И это действительно мощно. Лучше, чем собственное извлечение текста Adobe. Он извлек текст для меня, где другие инструменты (в том числе Adobe) действительно выплевывают только мусор.
Я просто протестировал автономный инструмент для настольных компьютеров, и то, что они говорят на своей веб-странице, верно. У него очень хорошая командная строка. Некоторые из моих “проблемных” файлов PDF файлов обрабатывают инструмент в полном объеме.
Теперь эта вещь будет моей рекомендацией для каждого сложного и сложного требования к извлечению текста в формате PDF.
TET просто потрясающе. Он обнаруживает таблицы. Внутри таблиц он идентифицирует ячейки, охватывающие несколько столбцов. Он определяет таблицы и содержимое каждой ячейки таблицы отдельно. Он отлично справляется с переносами: он удаляет дефисы и восстанавливает полные слова. Он поддерживает языки, отличные от ASCII (включая CJK, арабский и иврит). При встрече с лигатурами восстанавливаются исходные символы…
Попробуйте.
qaru.site
Перевод текста в pdf на русский язык « Инструменты для бизнеса
 Приветствую вас, уважаемые посетители моего блога Инструменты для бизнеса. Сегодняшний пост посвящен такому вопросу, как перевод текста в pdf формате с иностранного языка. Существует много источников полезной информации, однако, часть такой информации на иностранном языке. Хорошо, если на английском —одном из самых распространенном языке, а то и на других, менее распространенных, к тому же многим затруднительно переводить текст даже с английского.
Приветствую вас, уважаемые посетители моего блога Инструменты для бизнеса. Сегодняшний пост посвящен такому вопросу, как перевод текста в pdf формате с иностранного языка. Существует много источников полезной информации, однако, часть такой информации на иностранном языке. Хорошо, если на английском —одном из самых распространенном языке, а то и на других, менее распространенных, к тому же многим затруднительно переводить текст даже с английского.
Перевод текста в pdf формате и не только.
Прежде чем рассматривать перевод электронных книг, давайте рассмотрим перевод веб страниц. Ведь частенько поисковые системы выводят информацию на иностранных сайтах, а копировать и вставлять в какую-то программу иностранный текст не очень удобно.
Чтобы перевести текст веб страниц, стоит воспользоваться браузером хром, у которого переводчик встроен в ядро. Вам достаточно одобрить предложение хром перевести данный текст и вы сможете легко его прочитать на родном языке. Перевод, конечно, не художественный и не лингвистически обработанный, но главное, можно понять основную суть текста.
Если вы используете Mozilla FireFox, то рекомендую установить расширение IM Translator. Даное расширение работает с такими языками, как английский, испанский, итальянский, немецкий и французский. Помимо этого имеется многоязычная виртуальная клавиатура на 40 языков.
Для браузера Opera так же существует расширение. Скачать его можно по этой ссылке. Принцип работы тот же. Вы нажимаете на кнопочку перевести и страница автоматически обновляется, выводя текст на нужном языке.
Теперь самое интересное. Любой pdf файл можно открыть в браузере и, как вы наверное догадались, перевести, особенно, если файл был получен по электронной почте. Поэтому перевод текста в pdf можно сделать, нажав на просмотр файла из электронной почты.
Если файл pdf находится в вашем компьютере
Если файл находится на вашем жестком диске, то загружать его в интернет или настраивать ассоциацию файла с браузером не удобно, а может даже если и настроишь, работать не будет (я не пробовал, попробуйте). И чтобы перевести такой файл очень удобно воспользоваться программой dicter. Скачать программу можно с оф сайта. Программа бесплатная, поэтому ее не стоит искать на торрентах, только напрасно потратите время.
Во время установки стоит выбрать расширенный режим, чтобы не ставить яндекс-бар, если он у вас установлен или вы не хотите его устанавливать. После установки необходимо настроить программу.
1. Настройка клавиш для перевода.
По умолчанию для перевода текста установлено сочетание ctrl+alt (оба левые). Однако комбинацию можно изменить, щелкнув правой кнопкой мыши по значку в трее.

Далее нажимаем «Настройка клавиш для перевода» и нажимаем те клавиши, которые нужны для включения перевода текста в pdf.
Так же можно настроить размер шрифта, отображаемого в окне, всплывающем при нажатии клавиш для активации перевода.
Еще можно включить или отключить автозапуск программы, в зависимости от того, хотите ли вы, чтобы программа загружалась при загрузке системы.
Кстати, если значка нет в трее справа внизу у часов, то необходимо щелкнуть на стрелку
Далее находим нужный значок и справа от него выбираем «Отображать значок и уведомления».
Чтобы перевести нужный участок текста, необходимо выделить этот участок и нажать сочетание клавиш, которое мы настроили раньше. Появится окно с переведенным текстом.
Как видите, перевод текста в pdf не такая уж и проблема и можно смело изучать иностранную литературу.
А вы как переводите иностранные тексты и статьи?
Это вам будет интересно:
business-instrumenty.ru
Распознать текст из pdf в word
Время от времени может появиться необходимость в редактировании текста, который находится на картинке или в PDF документе. Конечно можно этот текст вначале вручную набрать, но если его много, то на это может уйти большое количество времени. В данной статье мы расскажем вам как при помощи программы ABBYY FineReader можно всего за пару минут без особого труда распознать в документ MS Word текст из документа PDF или с любого другого изображения.
Распознавание текста из PDF в Word программой FineReader
Найти, скачать и установить программу FineReader любой версии в интернете не составит труда. Достаточно написать в поисковике «Скачать Finereader». Для распознавания подойдет абсолютно любая версия данной программы.
Ярлык для запуска программы FineReader
После этого запустите программу через ярлык на рабочем столе. Если появится вот такое или подобное окно:
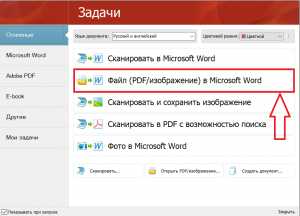
Окно при запуске FineReader
То для распознавания текста из PDF в Word нужно выбрать «Файл (PDF/Изображение) в Microsoft Word».
Если подобного окна при запуске FineReader не появляется, то в главном меню программы нужно выбрать «Файл» -> «Открыть PDF/ Изображение».
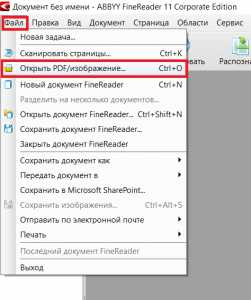
Переход к загрузке в программу документа PDF для распознавания
В обоих этих случаях появится окно, где нужно выбрать файл PDF, текст в котором нужно распознать и отправить в документ Word.
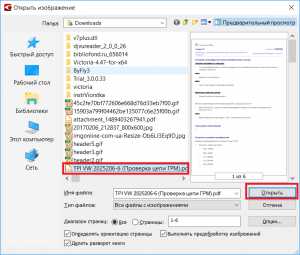
Выбор PDF документа
Выбираем и жмем кнопку «Открыть».
После этого автоматически начнется процесс распознавания текста из загруженного документа PDF.
Процесс распознавания
Результат распознавания вы увидите в правой части окна программы FineReader.
Рабочее окно программы FineReader
Чтобы отобразить распознанный текст в документе Microsoft Word нужно выбрать «Файл» -> «Передать документ в» -> «Microsoft Word».
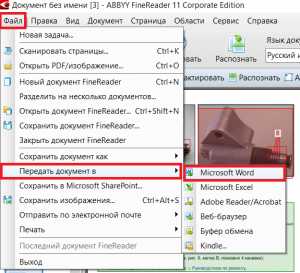
Отправка результатов распознавания в MS Word
Сразу после этого откроется новый документ Microsoft Word в котором будет все содержимое загруженного документа PDF, доступное для редактирования.
Документ Word с распознанным текстом из PDF
helpadmins.ru
CompUsers.ru » Как перенести текст из PDF в TXT без иероглифов (кракозябров)
На днях пришлось перенести некоторые отрывки текста из PDF-документа, а если точнее книги в обычный текстовый файл. Раньше для этих целей я использовал либо Adobe Reader либо Foxit Reader. Для этого в обеих программах есть функция экспорта текста. Делается это так: при открытом документе в Foxit Reader’е выбираем в меню «File» — «Save as…» в открывшемся окне задаем имя и выбираем тип файла «TXT files».
Но в последний раз появилась проблема. Текст с первых нескольки страниц книги PDF скопировался нормально, а дальше остальные страницы шли в виде каких-то иероглифов, так называемых кракозябров. Как я понял дело было в кодировках текста. Пытался поменять кодировки в «Notepad2», не помогло.
После непродолжительных поисков решения в интернете наткнулся на программу «Cool PDF Reader» скачал и попробовал. Программа бесплатна и сразу скажу не так удобна как две ранее упомянутые, но она вывела текст из моего проблемного PDF’а в нормальном виде. Никаких кракозябров, чистый текст. Но есть у нее один недостаток — «Cool PDF Reader» экспортирует текст по одной странице.
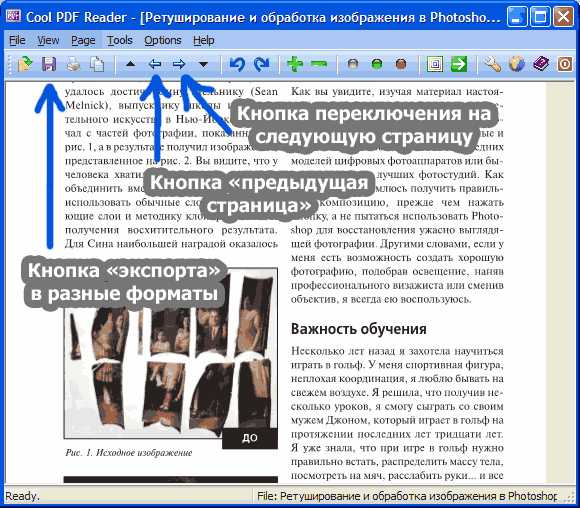
Для этого открываем в ней PDF-файл, переходим на нужную страницу с помощью кнопок сверху окна, и нажимаем кнопочку в виде дискеты, задаем имя будущего текстового файла и жмем «Сохранить».
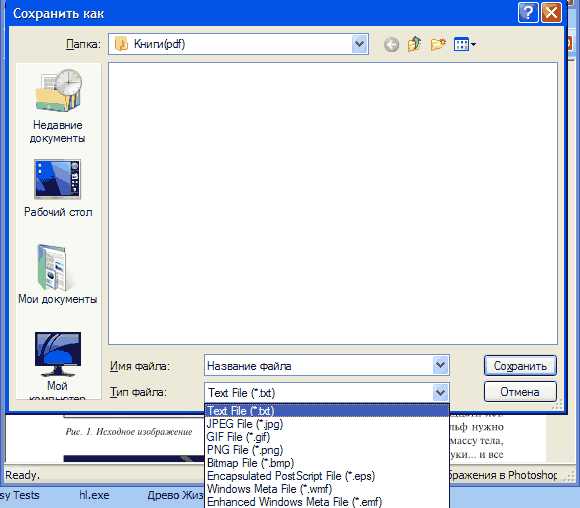
Если вам нужно получить из PDF-книг весь текст вы замучитесь, но если нужен отрывок, то пользоваться можно.
Данную программу можно скачать с нашего сайта.
Если вы знаете аналогичную программу, нормально экспортирующую текст из PDF-документов пишите в комментариях, допишу в статью.
compusers.ru
Как извлечь текст из PDF документа с помощью программы A-PDF.
Автор: admin
Категория: Конвертация
Дата: 12-01-2014
Количество просмотров: 1005
Предположим, вам нужно скопировать текст из PDF-файла, очевидно, вы не можете просто скопировать текст нажав ctrl+C и вставив в другой файл ctrl+V. Процесс немного сложнее. Прежде всего, необходимо, преобразовать его в текстовый файл. Бесплатный инструмент известный как A-PDF делает именно это. Вы можете
Скачайте и установите это небольшое приложение на ваш компьютер. Нажмите на кнопку «Открыть» и выберите PDF файл на вашем компьютере.
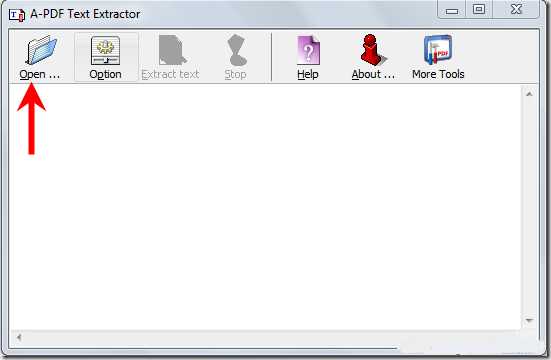
Программа покажет местоположение файла и количество страниц на его интерфейсе. Нажмите кнопку «Извлечь текст», чтобы начать процесс. Это займет несколько секунд, в зависимости от размера PDF файла.
Вы можете выбрать диапазон страниц, которые вы хотите извлечь. Например, если вы хотите извлечь от страницы 4 до страницы номер 6, заполните номер 4 и 6 в поле с заголовком «Страница из». Существует также вариант для извлечения текста из четных и нечетных страниц.
После преобразования появляется небольшое диалоговое окно с запросом, чтобы открыть извлеченный текстовый файл. Нажмите на кнопку «Да», чтобы открыть его в блокноте.
Вы можете столкнуться с некоторыми трудностями, если файл защищен паролем или имеет некоторые другие ограничения. Вы можете попробовать инструмент, известный как AnyBizSoft PDF Password Remover для удаления защиты с PDF файла.
Программа совершенно бесплатная, устанавливается в пару секунд, весит меньше мб.
Полученный текстовый файл вы можете перевести в формат word или в любой другой.
| Статус программы | Бесплатная |
| Операционная система | Windows 7,8, Vista, XP |
| Интерфейс | английский, русский |
| Версия программы | A-PDF |
| Категория | Текст -> Конвертация |
Скачать A-PDF
infoprosto.com
gPDFText – извлечение текста из PDF
Автор: admin.
Весь материал, я начисто “слизал” с другого ресурса, мне сегодня лень что-либо делать и думать головой, поэтому, читайте наздоровье, чужие мысли – то же хорошие мысли, если правда, так же не являются чужими, хотя, какая разница.
gPDFText – простой GTK+ редактор, позволяющий загружать текстовое содержимое PDF файлов (переформатируя абзацы в длинные строки), преобразовывая содержимое в простой текст. Приложение создано Нилом Вильямсом (Neil Williams). Многими приложениями для чтения PDF документов для отображения используется формат станиц A4 (или подобного размера). Когда документ открывается с масштабированием по экрану то на некоторых мониторах (устройствах чтения) текст получается слишком маленьким для чтения. Простой экспорт PDF документа в текст часто вызывает проблемы с переносом строк, а задание различных опций не оправданно усложняет автоматическое преобразование.
gPDFText открыв PDF документ извлечёт из него текст, автоматически переформатирует абзацы в отдельные строки и поместит текст в обычный текстовой редактор (где к тексту можно применять любые преобразования). Приложение имеет встроенный текстовой редактор, с проверкой орфографии, что может оказаться полезным при необходимости в редактировании текста (включение/отключение проверки орфографии в меню или по нажатию F7).Полученный текст не содержит нежелательных переносов строк, размер текста можно масштабировать до нужного размера, что может оказаться более удобным. параметры переформатирования могут быть изменены в настройках приложения.
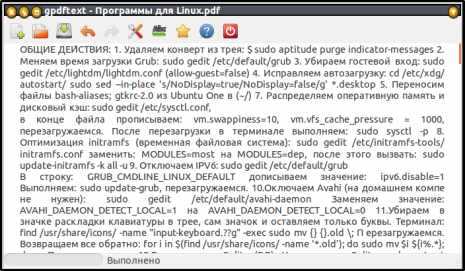
gPDFText извлекаемому тексту применяет три типа изменений… Это слияние слов с переносом, поддержка длинных строк (удаление ненужных разрывов строк), удаление колонтитулов (заголовочные данные, авторство, номера страниц и.т.д…), которые пользователь может отключить. Поддержка длинных строк позволяет объединить отдельные строки в первоначальный абзац, для того что бы устройство чтения смогло правильно их отформатировать. Удаление колонтитулов поддерживается частичен, удаляются только простейшие колонтитулы с номерами страниц. Если страниц PDF-документа содержат название книги, оглавление, встроенную рекламу и пр… То их придётся удалить вручную.
gPDFText не позволяет извлекать текст из файлов PDF, где текст размещён в таблицах или не в виде параграфов. Извлечённый и отредактированный текст может быть сохранён в .txt формате, или в новый файл PDF-файл на основе текста и с более подходящем размером страницы (A5 или B5), чтобы устройство чтения книг смогло отобразить страницу целиком и удобно масштабировало текст. Шрифт выбранный для редактора, также используется (того же размера) в создаваемом PDF. Любой текстовый файл также можно открыть и сохранить в PDF.
Положительные характеристики gPDFText:
- Легкое извлечение текста.
Отрицательные характеристики gPDFText:
- Не работает с таблицами.
Устанавливается и удаляется программа из “центра приложений Ubuntu“.
Параметры:
Язык интерфейса: русский
Лицензия: GNU GPL
Домашняя страница: http://gpdftext.sourceforge.net/
Проверялось на «Ubuntu» 13.04 Unity (64-bit.).
www.linux-info.ru
Как распознать текст из pdf?
Графический формат pdf является не только одним из самых популярных форматов в котором читают всевозможные книжки, журналы и т.д., но и так же, пожалуй, самым удобным форматов в котором можно отсканировать всевозможные тексты для их дальнейшего распознания и работы с ними. Тем более что большинство современных сканеров и мобильных приложений преобразуют сканированные копии текстов сразу в PDF формат.
Для того, чтобы распознать текст из pdf легко и быстро, можно воспользоваться бесплатной программой PDF-XChange Viewer. Сама по себе программа предназначена для просмотра файлов в pdf формате, однако у нее есть одна очень полезная функция, которая отличает эту программу от своих собратьев, это возможность распознавать текст.
И так, чтобы распознать текст из pdf следует после установки и запуска программы, на верхней панели инструментов нажать на кнопку OCR. Открывается окно настройки распознавания текста.
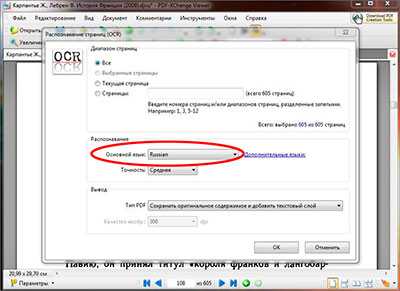
Первоначально в PDF-XChange Viewer русского языка для распознавания текста не установлено и поэтому, его надо дополнительно установить из дополнительного языкового пакета. Языковой пакет запускается из .exe файла двойным кликом по нему, в появившемся установочном окне следует выбрать нужным нам язык (естественно ставим галочку на против русского, ну или какого ни будь другого европейского языка если угодно) и устанавливаем пакет языков на компьютер.
После установки пакета перезагружаем программу и уже в меню «основной язык» устанавливаем русский язык.
После того как основной язык выбран, там же в настройках распознавания текста, так же можно выбрать сколько будет распознано страниц файл. Если страниц в pdf файле не много, то его можно распознать целиком, если же станиц очень много и они все не нужны, то для сохранения времени можно выбрать отдельные страницы для распознавания указав с какой по какую надо распознать. Так же можно распознать текст из pdf на текущей открытой странице выбрав соответствующий пункт в настройках.
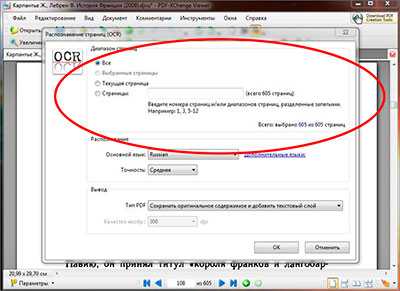
После того как выбран основной язык распознавания и нужные страницы файла, следует указать точность распознавания текста из pdf, их в программе PDF-XChange Viewer три степени: низкая, средняя и высокая. И соответственно, чем выше степень тем лучше будет распознавание, но и времени на обработку в высоком качестве будет потрачено больше чем в низком.
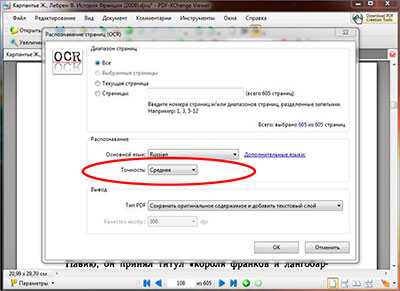
После того как нужный текст из pdf файла распознан, для того что бы его скопировать, следует на панели инструментов нажать на кнопку выделение (она выглядит как квадрат с буквой «Т») и выделить нужные фрагмент текста, а после нажать правой кнопкой мыши и выбрать строку копировать.
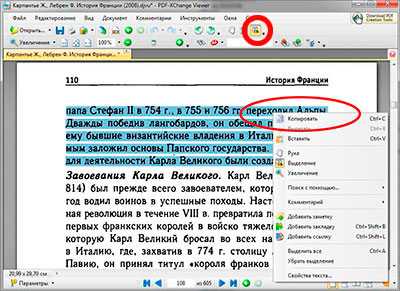
Сама же программа PDF-XChange Viewer является вполне хорошим и удобным просмотрщиком pdf файлов с возможностью вставлять комментарии в нужном месте текста, импортом и экспортом файлов данных, настройкой вида текста и окна программы и широкой панелью инструментов.
Распространение: бесплатное.
Операционная система: Windows XP, Windows Vista, Windows 7, Windows 8, Windows 10.
Сайт программы tracker-software.com/product/pdf-xchange-viewer-activex-sdk
softgayd.ru