
Pl sql developer план запроса: PL/SQL Developer Oracle – AskIt.RU
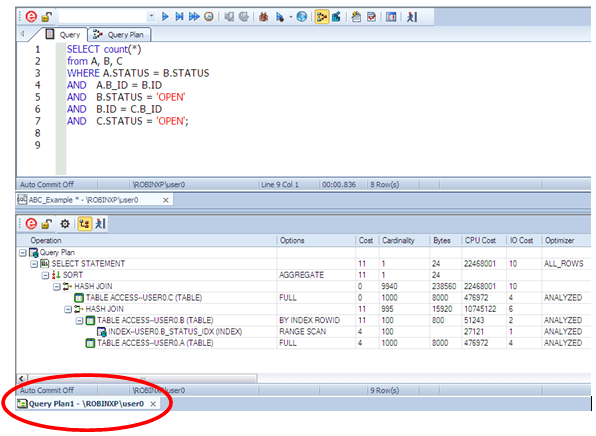
Приемы работы с планами выполнения запросов в Oracle
Это как гвоздь в подошве любимого ботинка. Ходить можно, но все чаще ловишь себя на желании остаться на месте или перепоручить дело другим. Мелкие неудобства не только замедляют нашу работу, но и снижают мотивацию, вносят помехи в процесс, снижают качество результата. И если нашелся друг, который научил вас взять молоток и забить этот гвоздь, вы не только будете благодарны ему за помощь, но и сами поможете другим, избавив их от мелкой, но очень раздражающей помехи. Для этого и нужно общаться, делиться не только глубокими и сокровенными знаниями в форумах и на сайтах вроде Хабра, но и своими простыми трюками и «маленькими хитростями»
Как и любой текст, запросы и программы на SQL можно создавать в любом текстовом редакторе. Но если вы профессионал, вы очень много и часто работаете с SQL, то вам уже не будет достаточно наличия подсветки синтаксиса и автоматического переформатирования кода, особенно, если вам приходится переключаться между различными версиями одной СУБД или разными платформами СУБД.
Недавно мне случилось общаться с одним из ведущих профессионалов СУБД Oracle. Он рассказал много интересного про работу с планами выполнения запросов в различных версиях этой СУБД и не постеснялся рассказать всем об используемых им инструментах, приемах и дать немного полезных мелких советов. Я сделал перевод одной из статей в его блоге и хотел бы предложить его вниманию Хабравчан. Несмотря на то, что описанный прием применялся для работы с Oracle, я теперь с успехом применяю тот же подход для MS SQL и Sybase.
Меня зовут Дан Хотка (Dan Hotka). Я директор Oracle ACE. Одной из моих привилегий в этой группе является помощь в распространении информации и полезных технических знаний, связанных с СУБД Oracle. Меня хорошо знают после моих 12 (скоро 14) опубликованных книг и буквально сотен статей. Я регулярно пишу в блоге и собираюсь делать это в дальнейшем. Мы даже могли встречаться на одном из событий или встреч группы пользователей. Я регулярно выступаю на эти темы по всему миру.
Я собираюсь поделиться с вами как техническими знаниями про Oracle, так и тем, как эти знания применяются в решениях Embarcadero.
Я скачал себе «большую тройку» продуктов Embarcadero: Rapid Sql, DBArtisan, DB PowerStudio. Сейчас я хотел бы рассказать о первом впечатлении и некоторых приемах работы с планами выполнения запросов в RapidSQL. (Я установил версию 8.6.1)
Я покажу пару приемчиков для планов выполнения запросов в и вокруг Rapid SQL.
Мне нравится инструмент. Конечно, это прекрасный инструмент, если у вас есть разные типы СУБД различных производителей, поскольку этот инструмент поддерживает около дюжины разных СУБД. Единый интерфейс для освоения всех БД! Мои приемчики относятся к Oracle. Но приемы для инструментов Embarcadero должны сработать вне зависимости от того, к какой СУБД вы подключились.
При просмотре планов выполнения я люблю видеть план выполнения и сам запрос одновременно.
Этого легко достигнуть.
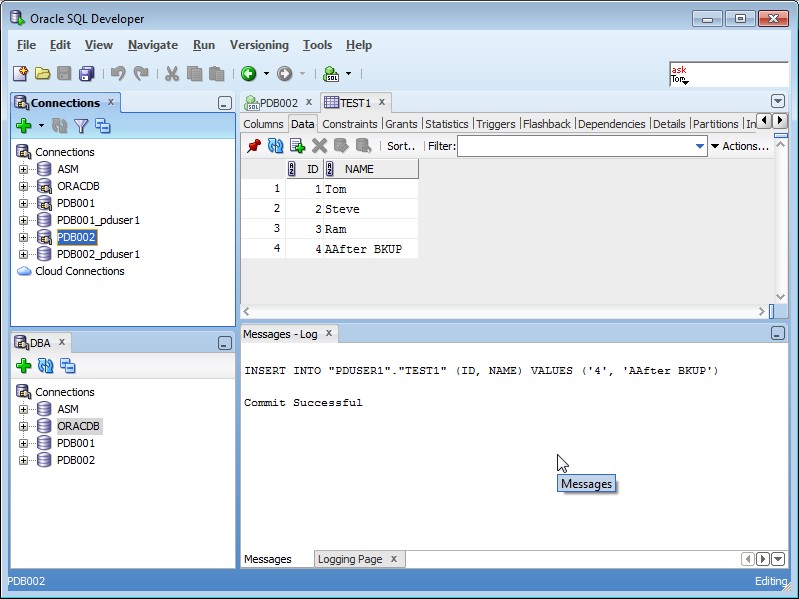
Для начала, загрузите свой SQL запрос в окно редактора ISQL (используя кнопку Open), затем включите кнопку Explain Plan (отмечена в красном круге). Кнопка останется активированной.
Кнопка останется активированной.
Запустите запрос на выполнение, и появится закладка Query Plan, заполненная планом выполнения.
Поместите курсор мыши на любой из узлов на диаграмме и появится дополнительная полезная информация, относящаяся к этому шагу выполнения из плана запроса!
По умолчанию, Rapid SQL показывает план выполнения в графическом виде. Я вышел из старого мира оптимизации…. Предпочитаю текстовую версию, поэтому нажимаю правую кнопку мыши в окне с планом и выбираю “View as Text”.
Предпочитаю видеть текст запроса и план одновременно.
Это легко сделать. Видите закладки окон ISQL внизу главного окна? Для начала мы должны настроить Rapid SQL, чтобы он выдавал план в отдельном окне.
Нажмите кнопку Options (левый красный кружок) и затем установите опцию ‘Unattached’ для Result window. Это приведет к созданию двух отдельных закладок внизу Rapid SQL, после запуска запроса на выполнение. Просто протащите немного это окно за закладку и появится прямоугольник, куда можно переместить это окно.
Или можно воспользоваться пунктом Tile windows из главного меню программы
И еще: все это так же работает и в DBArtisan — решении для администраторов баз данных.
via
Отчеты Oracle Sql Developer для анализа запросов
У каждого, кто работает с Бд Oracle есть набор любимых запросов для ее диагностики.В этой статье хотел бы описать мои, которые запускаются из Oracle Sql developer.
Выгрузка всех отчетов находится по ссылке github
Для работы необходимо наличие лицензии “Diagnostic and Tuning Pack”
Полный список всех отчетов можно видеть на картинке слева.
Большинство из них вспомогательные и нужны для определения параметров запуска отчета “ash” с более детальными параметрами
Вспомогательные отчеты
- Buffer Cache hit ratio – строит график с этим показателем.
Необходим для определения периода времени на котором были провалы по % буферных чтений. - Graph top – топ sql запросов по продолжительности в разрезе времени.

Может быть использован для наглядного определения наиболее долгих запросов в промежуток времени. - Reads per sec – график логических или физических чтений в разрезе времени
Используется для определения проблемного промежутка времени в который было повышенное число чтений - Table top reads – гистограмма со списком топовых таблица по чтениям в указанный период
Используется как детализация отчета “Reads per sec” за указанный период, чтобы узнать какая именно таблица вызвала повышенные чтения. - Нагрузка ash – график числа sample ash в разрезе времени
Наглядное определение периода времени, в который была наибольшая активность запросов. По проблемному периоду дальше строится детализирующий отчета “ash” - Нагрузка по неделям – график числа sample ash в разрезе дня недели и номера недели
Удобно для анализа динамики нагрузки на бд. - Obj top read – топ запросов по чтениям на заданной таблице.
Используется как детализация отчетов “Reads per sec” -> “Table top reads”, чтобы узнать какие именно запросы вызвали повышенные чтения на указанной таблице. - Query on obj – топ запросов по времени на заданной таблице.
- Таблицы в кэше – таблицы, которые сейчас в буферном кэше находятся в представлении v$bh
Чтобы иметь историю представление материализуется в таблицу каждый час запросом, а потом строится график:insert into stat$bh(snap_date, objd, obj_owner, obj_type, obj_name, obj_blocks, blocks, pct, dirty_blocks) select sysdate as snap_date, objd, obj_owner, obj_type, obj_name, obj_blocks, blocks, pct, dirty_blocks from ( select objd, o.owner as obj_owner, o.object_type as obj_type, o.object_name as obj_name, max(NVL(t.Постоянный большой объем таблицы в кэше говорит о неоптимальности запросов на ней, т.к. вычитывается большой объем данных. blocks, i.LEAF_BLOCKS)) as obj_blocks,
count(*) blocks,
ROUND(count(*) / SUM( COUNT(*) ) OVER() * 100,2) pct,
count(case when s.dirty = 'Y' then 1 end) dirty_blocks
from
GV$BH s
join dba_objects o on o.object_id = s.objd
left join dba_tables t on t.table_name = o.object_name and t.owner = o.owner
left join dba_indexes i on i.index_name = o.object_name and i.owner = o.owner
group by
inst_id,
objd,
o.object_type,
o.object_name,
o.owner
)
where pct > 0.5
order by pct desc;
По dirty_blocks можно косвенно оценить объем изменений. - Query ash now – список сейчас работающих запросов.
Есть возможность наложить фильтр по клиенту, программе, sql_id, id сессии, тексту запроса. - Plan diff date – поиск изменившихся планов между 2 датами.
Удобно при анализе изменившихся планов после установки патчей на бд. - SQL id plans, Table plans – устаревшие отчеты, которые стали частью других: “ash” и “Query on obj” соответственно.

 blocks, i.LEAF_BLOCKS)) as obj_blocks,
count(*) blocks,
ROUND(count(*) / SUM( COUNT(*) ) OVER() * 100,2) pct,
count(case when s.dirty = 'Y' then 1 end) dirty_blocks
from
GV$BH s
join dba_objects o on o.object_id = s.objd
left join dba_tables t on t.table_name = o.object_name and t.owner = o.owner
left join dba_indexes i on i.index_name = o.object_name and i.owner = o.owner
group by
inst_id,
objd,
o.object_type,
o.object_name,
o.owner
)
where pct > 0.5
order by pct desc;
blocks, i.LEAF_BLOCKS)) as obj_blocks,
count(*) blocks,
ROUND(count(*) / SUM( COUNT(*) ) OVER() * 100,2) pct,
count(case when s.dirty = 'Y' then 1 end) dirty_blocks
from
GV$BH s
join dba_objects o on o.object_id = s.objd
left join dba_tables t on t.table_name = o.object_name and t.owner = o.owner
left join dba_indexes i on i.index_name = o.object_name and i.owner = o.owner
group by
inst_id,
objd,
o.object_type,
o.object_name,
o.owner
)
where pct > 0.5
order by pct desc;
Основной детализирующий отчет ASH
При запуске нужно минимум указать 2 параметра:- f – дата-время С целиком или часть (dd.mm.yyyy hh34:mi:ss)
- t – дата-время ПО целиком или часть (dd.mm.yyyy hh34:mi:ss)
- module – программа (возможно задание маской %%)
- client – пользователь/client_id (возможно задание маской %%)
- sql_id – id запроса (точное совпадение)
- hsh – hash плана запроса (точное совпадение)
- st_hr – начальный час анализа (точное совпадение)
- ed_hr – конечный час анализа (точное совпадение) – когда нужно проанализировать определенный часовой промежуток, но за несколько дней (к примеру только запросы в рабочее время 8-18)
- event – запросы содержащие это событие (точное совпадение)
- sid – запросы от указанного id сессии (точное совпадение)
- user_id – запросы от указанного id пользователя (точное совпадение)
- smpl – 0 – сортировать запросы по времени работы. 1 – по числу sample в ash.
Топ в зависимости от настройки может отличаться, т.к. параллельные запросы работают по времени меньше, чем создают samples от параллельных потоков в истории.
 1 – по числу sample в ash.
1 – по числу sample в ash.После задания параметров открывается главная форма отчета:
Форма собирается из 3 таблиц: gv$active_session_history – недавняя история ASH, dba_hist_active_sess_history – давняя история и DBA_HIST_SQLSTAT – количественные показатели (число выполнений, время работы, число строк)
Кроме столбцов, которые известы из параметров отчета, добавляются:
* st_dt/ed_dt – период, на котором наблюдался запрос
* gb – объем считанных данных в ГБ
* av_sec – среднее время работы
* sec – суммарное время работы
* smpl – суммарное число sample в ash
* dop – степень параллелизма, с которой работал запрос
* rws – числ отбираемых/изменяемых строк
* prc – % времени запроса от общей
* txt – текст запроса
Если поставить фокус на определенной строчке отчета, то активируются детализирующие отчеты:
* sql_id plans – список планов на этом запросе за все время существования.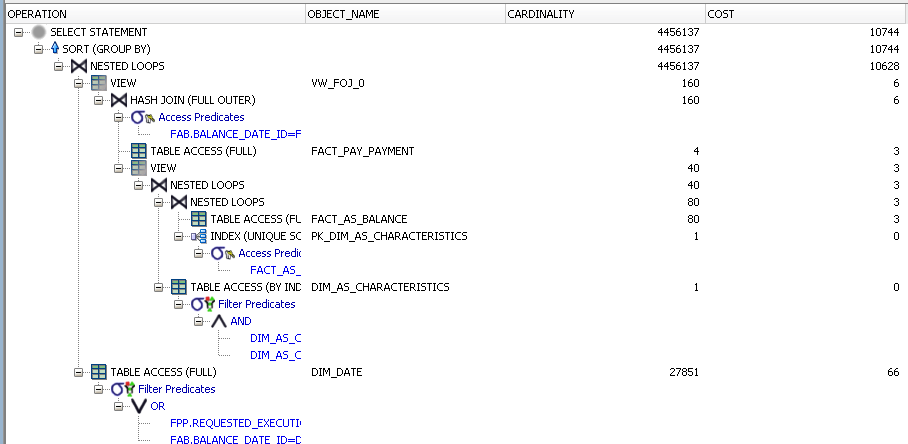
+ Характеристики каждого плана: когда он выполнялся, число выполнений, объем физических и логических чтений, число строк, среднее время и отклонение времени работы от среднего.
Данный детализирующий отчет удобен для выбора плана для последующей фиксации по средствам baseline.
* ash now – сейчас исполняющиеся запросы:
* plan – максимально детальный план запроса:
* binds – историй биндов запроса
* v$sql – информация о запросе из v$sql:
Список child планов, наличие профиля или baseline и все количественные характеристики child планов:
* awr – количественные характеристики плана в разрезе снапшотом без агрегации
* text – полный текст запроса:
* plan real – детализация плана запроса:
** план запроса
** предикаты доступа к объекту (если план сейчас в кэше)
** полный список колонок используемого индекса (для анализа эффективности индекса на месте)
** event – список событий этой строчки плана с процентным распределением от общего времени запроса
** prc – % времени работы этой строчки плана.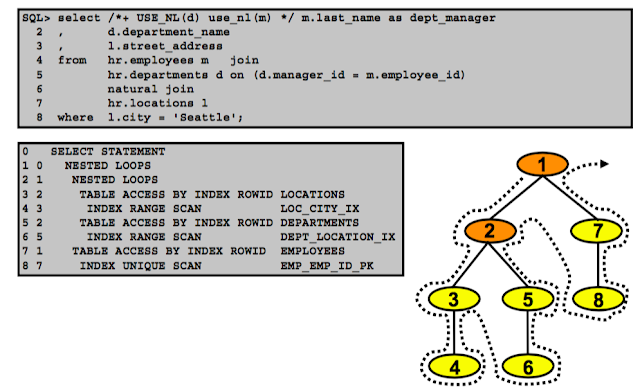
Удобно для быстрого определения неоптимальной части запроса, которую требуется оптимизировать в первую очередь.
* graph – график суммарного времени работы запроса в разрезе часов.
* awr wk – аналог отчета awr, но с группировкой до недели.
Удобно для определения тренда времени запроса и определения времени, когда сменился план.
* objects – топ таблиц по времени обращения к ним от этого запроса
* v$bh – история объема таблиц запроса в буферном кэше (источник: отчет “Таблицы в кэше”)
* module – топ программ, которые взывают этот запрос
* graph_exe – график, аналогично отчету “graph”, но по числу выполнений запроса.
Удобно сравнивать graph и graph_exe между собой, чтобы визуально видеть, растет ли число выполнений запроса вместе с общим временем.
Если число выполнений не растет, а общее время растет, то вероятная причина – рост среднего времени запроса.
* список сессий, которые блокировки работу выделенного запроса
** Событие блокировки
** клиент, который блокировал работу
** id сессии блокировки
** current_* – блок и строка в блоке, на которой происходила блокировка.
** obj_name – Объект, на котором блокировка
** cnt – количество sample во время которых длилась блокировка.
** sql_text – текст запроса, для определения строчки, на которой висела блокировка (на основании current_* столбцов)
Данный отчет удобно использовать для определения горячих строк, к которым пытаются получить блокировку несколько процессов.
* plan real tbs – на каком tablespace были основные чтения у строк плана запроса.
Данный отчет удобен для понимания причин замедления запроса, у которого не поменялся план
Скорей всего замедление связано с ростом числа чтений сегментом отката UNDO из-за интенсивной вставки/обновления одной из таблиц запроса ранее.
* text_bnd – Запрос с подставленным параметрами на место биндов.
Удобно для проверки влияния биндов на план запроса. Если с подставленными значениями получается хороший план, то вероятная причина в перекосе данных или отсутствующих гистограммах.
Выгрузка всех отчетов находится по ссылке github
oracle.
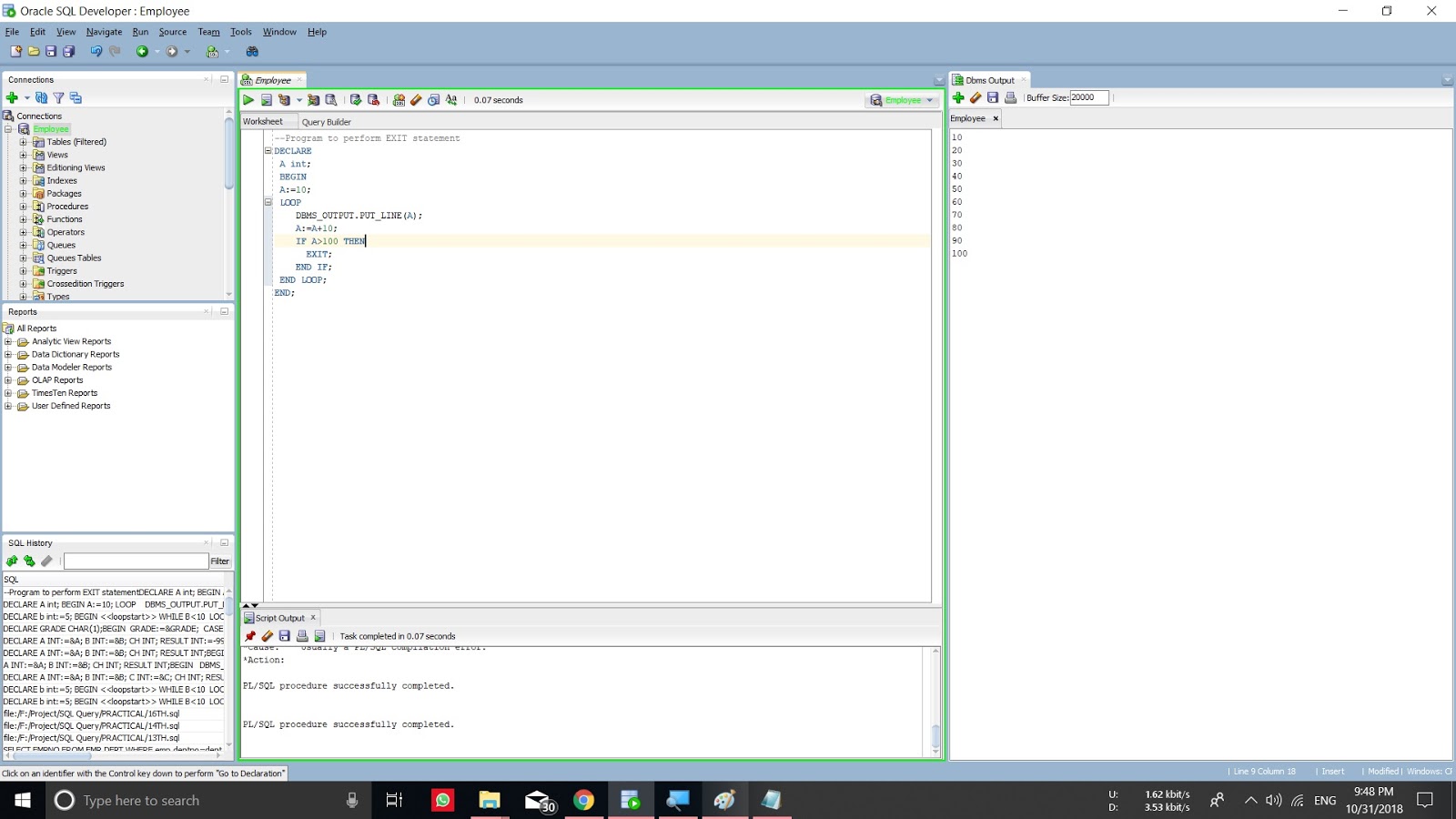
 notes: PL/SQL Developer session window
notes: PL/SQL Developer session windowВ окне списка сессий PL/SQL Developer (Tools -> Sessions) можно добавить кучу полезных вкладок, которые будут выполнять скрипты и запросы, получая любое значение из подсвеченной сессии в списке через :[ИМЯ_КОЛОНКИ v$session]. В настоящее время в стоковом PL/SQL Developer (версия 11) есть 5 вкладок:
Cursors
SQL Text
Statistics
Locks
Sql Monitor
Добавлять свои вкладки можно при помощи кнопки с гаечным ключиком -> Details
В настоящий момент я использую
План запроса dbms_xplan
Особое внимание /* concatenate */ из последней строчки – результат будет сцеплен в одно поле, его можно скопировать и вставить в другое окно для детального анализа.
SELECT t.plan_table_output || CHR(10) plan_table_output
FROM table(dbms_xplan.display_cursor(:sql_id, :sql_child_number,format => 'ADVANCED')) t
План запроса из v$
SELECT decode(id, 1, child_number) || decode(:sql_address, '00', '-P') AS c,
output_rows AS tot_r,
last_output_rows AS r,
rpad(' ', depth * 3) || operation || ' ' || options ||
nvl2(object_name, ' -> ', '') || object_name AS op,
cost,
cardinality AS card,
bytes,
access_predicates AS "ACCESS",
filter_predicates AS filter,
round(temp_space / 1024 / 1024) AS temp_mb,
partition_start || nvl2(partition_start, ' - ', '') || partition_stop AS p,
partition_id,
other,
other_tag,
cpu_cost,
io_cost,
distribution,
object_owner,
optimizer,
position,
search_columns,
executions,
last_starts,
starts,
last_cr_buffer_gets,
cr_buffer_gets,
last_cu_buffer_gets,
cu_buffer_gets,
last_disk_reads,
disk_reads,
last_disk_writes,
disk_writes,
round(last_elapsed_time / 1000000, 2) AS last_ela_time,
round(elapsed_time / 1000000, 2) AS elapsed_time,
policy,
estimated_optimal_size,
estimated_onepass_size,
last_memory_used,
last_execution,
last_degree,
total_executions,
optimal_executions,
onepass_executions,
multipasses_executions,
round(active_time / 1000000, 2) AS active_time_avg,
max_tempseg_size,
last_tempseg_size
FROM (SELECT *
FROM v$sql_plan_statistics_all
WHERE address = hextoraw(:sql_address)
AND hash_value = :sql_hash_value
UNION ALL
SELECT *
FROM v$sql_plan_statistics_all
WHERE address = hextoraw(:prev_sql_addr)
AND hash_value = :prev_hash_value) t
CONNECT BY address = PRIOR address
AND hash_value = PRIOR hash_value
AND child_number = PRIOR child_number
AND PRIOR id = parent_id
START WITH id = 1
ORDER BY address, hash_value, child_number DESC, id, positionSQL Workarea
Объем памяти, потребляемой сессией. Правда не очень часто пригождается
Правда не очень часто пригождается
SELECT operation_type,
policy,
estimated_optimal_size,
estimated_onepass_size,
last_memory_used,
last_execution,
last_degree,
total_executions,
optimal_executions,
onepass_executions,
multipasses_executions,
active_time,
max_tempseg_size,
last_tempseg_size
FROM v$sql_workarea
WHERE address = hextoraw(:sql_address)
AND hash_value = :sql_hash_valueТаким способом достаточно удобно заниматься troubleshooting’ом, если известа сессия, которая испытывает проблемы. Очень удобный и мощный механизм.
oracle-spatial — Русский — it-swarm.com.ru
oracle-spatial — Русский — it-swarm.com.ruit-swarm.com.ru
как получить широту и длину от sdo_geometry в оракуле
Каков наилучший способ хранения координат (долгота/широта от Google Maps) в SQL Server?
SQL Server 2008 Spatial: найти точку в многоугольнике
Простой способ для подстановки SpatialPolygonsDataFrame (т. е. удалить полигоны) по атрибуту в R
е. удалить полигоны) по атрибуту в R
Обрезать для SpatialPolygonsDataFrame
Hibernate Spatial 5 – GeometryType
Как я могу сделать пространственное соединение с пакетом sf, используя st_join ()
Сбой при загрузке приложения Spring Метод org.postgresql.jdbc4.Jdbc4Connection.createClob () еще не реализован
Изменить параметры набора символов NLS в Oracle 11g XE
Как вы подключаетесь к базе данных MySQL с помощью Oracle SQL Developer?
Распечатать текст в окне Oracle SQL Developer SQL Worksheet
Поддерживает ли SQLDeveloper выполнение скриптов?
Можно ли вывести инструкцию SELECT из блока PL/SQL?
Имена Oracle TNS не отображаются при добавлении нового соединения в SQL Developer
Домашняя страница Oracle 10g express не появится
Понимание результатов выполнения плана объяснения в Oracle SQL Developer
Формат строки URL для подключения к базе данных Oracle с JDBC
Экранирующий символ Oracle SQL (для символа ‘&’)
Как найти, какие таблицы ссылаются на данную таблицу в Oracle SQL Developer?
как установить нулевое значение для поля в таблице с помощью инструмента разработчика Oracle SQL?
Как перенаправить вывод DBMS_OUTPUT.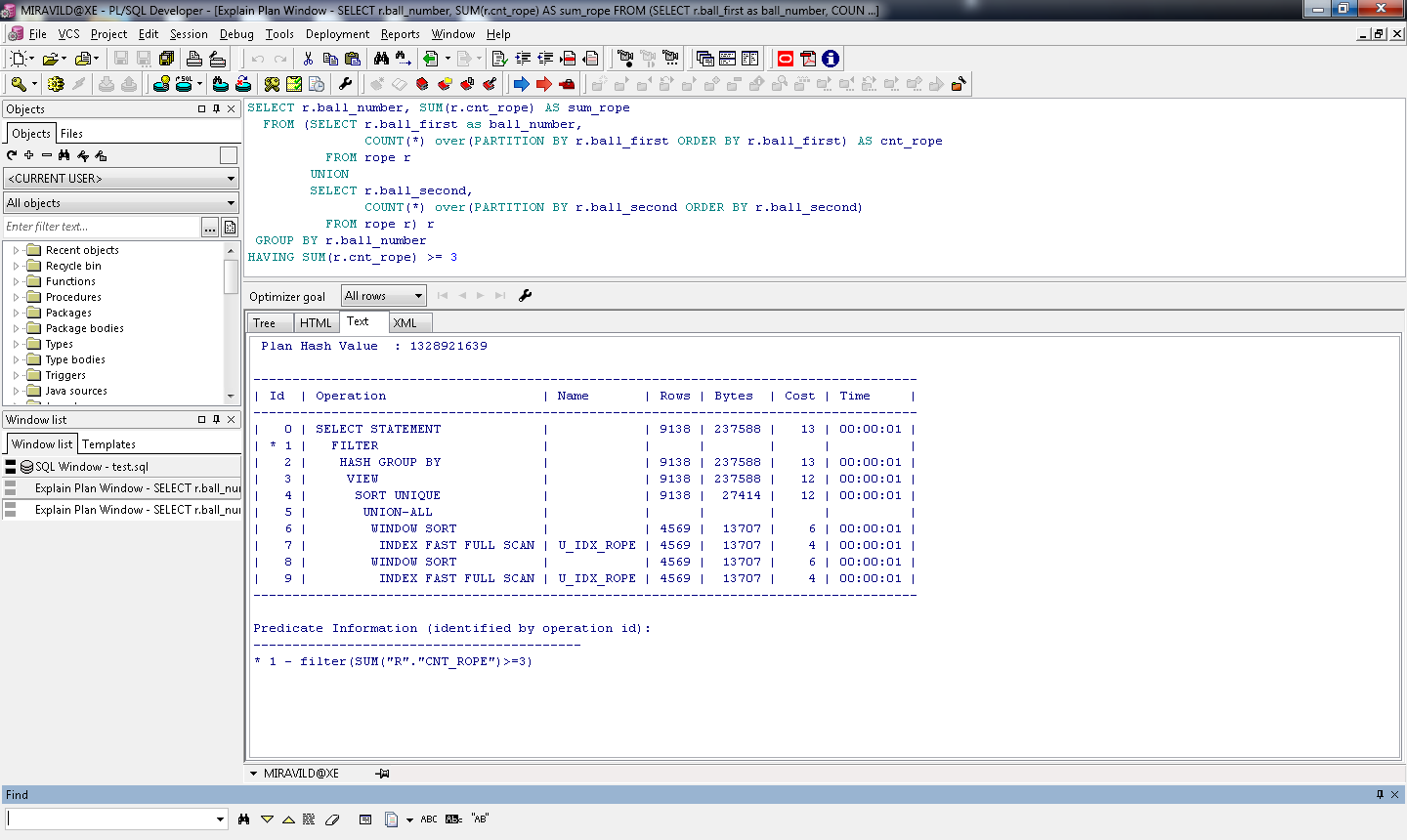 PUT_LINE в файл?
PUT_LINE в файл?
вставить если не существует оракул
Oracle “Ошибка SQL: отсутствует параметр IN или OUT в index :: 1”
Используйте tnsnames.ora в Oracle SQL Developer
Как избежать подстановки переменных в Oracle SQL Developer с помощью “Тринидад и Тобаго”
Как экспортировать данные с Oracle SQL Developer?
Как правильно установить переменную Oracle_HOME в Ubuntu 9.x?
Изменение пароля с Oracle SQL Developer
Выполнить 2 запроса одновременно в Oracle SQL Developer?
Найдите длину самого длинного ряда в колонке оракула
Как я могу получить доступ к Oracle из Python?
Как получить красиво отформатированные результаты из процедуры Oracle, которая возвращает ссылочный курсор?
Oracle SQL Developer – окно результатов запроса с отсутствующей сеткой
Запустить хранимую процедуру в SQL Developer?
Как экспортировать результат запроса в csv в Oracle SQL Developer?
Как ввести специальные символы, такие как «&» в базе данных Oracle?
Разница между VARCHAR2 (10 символов) и NVARCHAR2 (10)
Oracle SQL Developer – таблицы не видны
Как посмотреть, завершен ли фоновый процесс в SQL DEVELOPER
Как создать диаграмму сущности-отношения (ER) с помощью Oracle SQL Developer
Явно установите значение столбца в нулевой SQL Developer
Как изменить настройки для разработчика SQL, чтобы правильно распознать текущую версию SDK
Как я могу вставить в столбец BLOB из оператора вставки в sqldeveloper?
Печать значения переменной в SQL Developer
Как установить пользовательский формат даты и времени в Oracle SQL Developer?
Oracle 11g Express Edition для Windows 64bit?
Как увеличить размер буфера в Oracle SQL Developer для просмотра всех записей?
Как запросить имя базы данных в Oracle SQL Developer?
Создание списка словарей с помощью cx_Oracle
Данные, принятые в другом/том же сеансе, не могут обновить строку (Oracle SQL Developer)
Как объявить и использовать переменные в PL / SQL, как в T-SQL?
Как установить автоинкрементный столбец с SQL-разработчиком
Расположение спула Oracle
Модуль Python “cx_Oracle” модуль не найден
“ошибка: не удается найти установку программного обеспечения Oracle” при попытке установить cx_Oracle
Oracle: экспортировать таблицу с BLOB-объектами в файл . sql, который можно снова импортировать
sql, который можно снова импортировать
Показать все представления в базе данных Oracle
Ссылка для начала работы не работает на сервере Oracle 11g
Какова максимальная длина оператора в Oracle
Найти таблицу по запросу имени столбца в Oracle SQL Developer
Как извлечь номер недели в sql
Oracle SQL Developer вывод спула?
Как изменить схему по умолчанию в SQL Developer?
Как исправить ошибку «Поставщик не совместим с версией клиента Oracle»?
Создание новой базы данных и нового соединения в Oracle SQL Developer
Буферная команда: не выводить оператор SQL в файл
Создать несколько таблиц, используя один файл скрипта .sql
Полный путь установки JDK для Oracle SQL Developer
Как использовать переменную даты в диалоге sql разработчика “Enter Binds”?
ORA-12505, TNS: слушатель в настоящее время не знает о SID, указанном в соединении
Oracle SQL Developer: сбой – тест не пройден: сетевой адаптер не может установить соединение?
cx_Oracle не подключается при использовании SID вместо имени службы в строке подключения
скопировать из одной базы данных в другую с помощью Oracle sql developer – ошибка подключения
Настройка NLS_NUMERIC_CHARACTERS для десятичной
Старая история SQL в Oracle SQL Developer
SQL-Developer: не могу открыть программу
Sql разработчик пользовательские строки подключения
Удалить заголовок столбца в выходной текстовый файл
Как просмотреть план объяснения в Oracle Sql для разработчиков?
PLSQL генерирует случайное целое число
Как я могу решить Получил минус один от разработчика Oracle SQL?
Извлечь число из строки с помощью функции Oracle
Oracle sql заказать с заявлением
Ярлык выделенного текста в верхнем регистре в Oracle SQL Developer
Как сделать, чтобы sql разработчик отображал не английский символ правильно вместо отображения квадратов?
Как создать пустой / пустой столбец с запросом SELECT в Oracle?
как изменить размер столбца
Порядок столбцов интерактивного отчета APEX 5
Закройте модальную диалоговую страницу и обновите страницу Oracle APEX
Oracle SQLDeveloper на MacOS не открывается после установки правильного Java
Редактирование меню “Row-Action” в APEX Interactive Grid
Проблема при установке Oracle 18cxe на Ubuntu 18. 04
04
Как импортировать дамп Oracle в другое табличное пространство
Какой минимальный размер клиентского пространства необходим для подключения C # к базе данных Oracle?
Что такое двойная таблица в Oracle?
В чем разница между явными и неявными курсорами в Oracle?
Как часто следует запускать статистику базы данных Oracle?
Как вы интерпретируете план объяснения запроса?
Разница между BYTE и CHAR в типах данных столбцов
Можете ли вы использовать Microsoft Entity Framework с Oracle?
Content dated before 2011-04-08 (UTC) is licensed under CC BY-SA 2.5. Content dated from 2011-04-08 up to but not including 2018-05-02 (UTC) is licensed under CC BY-SA 3.0. Content dated on or after 2018-05-02 (UTC) is licensed under CC BY-SA 4.0. | PrivacyУчимся оптимизировать SQL-запросы и понимать планы выполнения
Поскольку вы ищете специфическую информацию для Oracle, я бы порекомендовал блог Ask Tom в Oracle. В общем, думаю, вы найдете совет не настраивать запрос. Вы получите хороший совет о том, как написать запрос, который оптимизатор может оптимизировать. Документация по Oracle также доступна онлайн , и я обычно ищу там актуальную информацию по Oracle. Я не работал с SQLServer, поэтому у меня нет никаких рекомендаций для него.
Вы получите хороший совет о том, как написать запрос, который оптимизатор может оптимизировать. Документация по Oracle также доступна онлайн , и я обычно ищу там актуальную информацию по Oracle. Я не работал с SQLServer, поэтому у меня нет никаких рекомендаций для него.
За последние несколько лет я не видел много нового в области оптимизации запросов. Большим изменением является устаревший оптимизатор на основе правил, с которым я едва помню, как работал. Однако я понимаю, что SQLServer по-прежнему использует оптимизатор на основе правил, поэтому понимание его правил может помочь.
Инструмент, с помощью которого вы можете отредактировать запрос, выполнить его и создать план объяснения, помогает понять, какие изменения приводят к успешному выполнению запроса. У меня были хорошие результаты с AquaData Studio, и мне действительно нравится его древовидная структура. SQL Developer должен делать то же самое.
Как и при любой оптимизации, вам необходимо иметь количественные данные о ее производительности. Затем вы можете определить, действительно ли вы его оптимизировали.
Затем вы можете определить, действительно ли вы его оптимизировали.
Как оптимизировать запрос частично зависит от того, как синтаксический анализатор строит и оптимизирует запрос. В большей степени это зависит от распределения запрашиваемых данных. В базе данных Oracle, если результирующий набор составляет четыре процента или более от таблицы и распределен случайным образом, сканирование таблицы обычно выполняется быстрее, чем индекс.
Я работал над оптимизацией запросов для команды разработчиков. Только два или три запроса в год требовали серьезной оптимизации. Большинство запросов достаточно просты, поэтому они не нуждаются в оптимизации. Остальные обычно могут быть обработаны путем добавления отсутствующих путей соединения.
Для Oracle есть три настраиваемых параметра, которые могут существенно повлиять на производительность. Стоимость поиска индекса и данных взаимодействует, изменяя условия, при которых индекс будет использоваться или не будет использоваться. Эти два могут быть настроены для каждой сессии. Значения по умолчанию часто не оптимальны. Другое значение определяет, сколько альтернатив будет использовать оптимизатор. Увеличение этого значения часто помогает.
Эти два могут быть настроены для каждой сессии. Значения по умолчанию часто не оптимальны. Другое значение определяет, сколько альтернатив будет использовать оптимизатор. Увеличение этого значения часто помогает.
Оптимизация существенно зависит от распределения данных и объема. При его оптимизации лучше всего использовать копию рабочей базы данных или, по крайней мере, базу данных с таким же распределением данных и томами. Я серьезно нарушил среду тестирования, оптимизировав запрос для базы данных производственных заказов. Базы данных для тестирования и разработки имели существенно различное распределение данных, что приводило к сбою запроса даже при значительно меньшем количестве данных.
Команды меню и другие сочетания клавиш (Oracle to SQL) – SQL Server
-
 date”>01/19/2017
date”>01/19/2017 - Чтение занимает 6 мин
В этой статье
В следующих разделах описываются сочетания клавиш для доступа к командам меню и другие сочетания клавиш, используемые в различных диалоговых окнах приложения SSMA для Oracle.
команды меню “Файл”
Для доступа к меню “файл” используется сочетание клавиш ALT + F. В следующей таблице описаны сочетания клавиш, используемые для доступа к пунктам меню «файл».
| ДЛЯ ЭТОГО | НАЖАТЬ |
|---|---|
| Отображение диалогового окна Новый проект. | ALT + F + N |
| Отображение диалогового окна Открытие проекта. | ALT + F + O |
| Закрытие текущего проекта. | ALT + F + C |
| Отображение диалогового окна Сохранить проект. | ALT + F + S |
Отображение диалогового окна Подключение или повторное подключение к Oracle. | ALT + F + T |
| Отображение диалогового окна Подключение или повторное подключение к SQL Server или SQL Azure. | ALT + F + Q |
| Доступ к последним проектам. | ALT + F + P |
| Закройте приложение SSMA. | ALT + F + X |
Команды меню “Правка”
Для доступа к меню “Правка” используется сочетание клавиш ALT + E. В следующей таблице описаны сочетания клавиш, используемые для доступа к пунктам меню в меню Правка.
| ДЛЯ ЭТОГО | НАЖАТЬ |
|---|---|
| Вырезание выделенного текста в буфер обмена. | ALT + E + T или CTRL + X |
| Копировать выделенный текст в буфер обмена. | ALT + E + C или CTRL + C |
| Вставка последнего добавленного текста из буфера обмена. | ALT + E + P или CTRL + V |
| Отменить последнее действие. | ALT + E + U или CTRL + Z |
Повтор или повторение действия. | ALT + E + R или CTRL + Y |
| Отображение диалогового окна Управление закладками. | ALT + E + B или CTRL + X |
| Переход к строке | ALT + E + G или CTRL + G |
| Сохраните изменения, выполненные в инструкции. | ALT + E + S или CTRL + S |
| Подменю доступа “найти”. | ALT + E + F |
| Поиск или быстрый поиск. | ALT + E + F + F или CTRL + F |
| Отображение диалогового окна Расширенный поиск. | ALT + E + F + A или ALT + F12 |
| Запустить краткие сведения. | ALT + E + F + I или CTRL + SHIFT + ПРОБЕЛ |
| Переход к объявлению. | ALT + E + F + G или F12 |
| Найти ранее. | ALT + E + F + P или CTRL + SHIFT + F3 |
| Найти далее | ALT + E + F + N или CTRL + F3 |
Команды меню “Вид”
Для доступа к меню «Вид» используется сочетание клавиш ALT + V. В следующей таблице описаны сочетания клавиш, используемые для доступа к пунктам меню в меню Вид.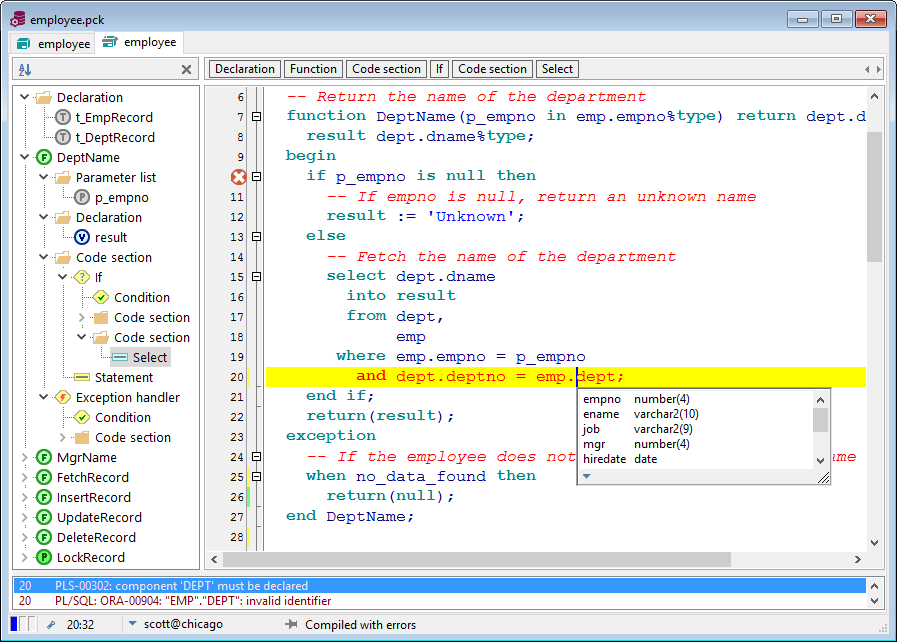
| ДЛЯ ЭТОГО | НАЖАТЬ |
|---|---|
| Синхронизация обозревателей метаданных. | ALT + V + Z |
| Отобразить дерево. | ALT + V + H или CTRL + T |
| Отобразить исходный фрагмент. | ALT + V + S |
| Отображение целевой части. | ALT + V + T |
| Отобразить панель списка ошибок. | ALT + V + E или CTRL + E |
| Отображение области вывода. | ALT + V + O или CTRL + O |
| Подменю “макеты Access”. | ALT + V + L |
| Добавить текущий макет. | ALT + V + L + A |
| Выберите макет по умолчанию. | ALT + V + L + D или CTRL + ALT + 1 |
| Выберите без макета проводника. | ALT + V + L + W или CTRL + ALT + 2 |
| Отображение диалогового окна Управление макетами. | ALT + V + L + M |
Для доступа к меню “Сервис” используется сочетание клавиш ALT + T. В следующей таблице описаны сочетания клавиш, используемые для доступа к пунктам меню в меню Сервис.
В следующей таблице описаны сочетания клавиш, используемые для доступа к пунктам меню в меню Сервис.
| ДЛЯ ЭТОГО | НАЖАТЬ |
|---|---|
| Создать отчет. | ALT + T + C |
| Преобразование схемы. | ALT + T + N или CTRL + R |
| Обновление из базы данных Oracle. | ALT + T + R |
| Синхронизируйте с SQL Server или с базой данных SQL Azure. | ALT + T + S |
| Сохранить как скрипт. | ALT + T + A |
| Перенос данных. | ALT + T + M |
| Останавливает текущую операцию. | ALT + T + O |
| Отображение диалогового окна глобальные параметры. | ALT + T + G |
| Отображение диалогового окна «Параметры проекта». | ALT + T + P |
| Отображение диалогового окна «Параметры проекта по умолчанию». | ALT + T + J |
Команды меню “Тестер”
Для доступа к меню тестера используется сочетание клавиш ALT + S. В следующей таблице описаны сочетания клавиш, используемые для доступа к пунктам меню в меню тестеров.
В следующей таблице описаны сочетания клавиш, используемые для доступа к пунктам меню в меню тестеров.
| ДЛЯ ЭТОГО | НАЖАТЬ |
|---|---|
| Отображение диалогового окна Мастер тестовых случаев. | ALT + S + N |
| Отображение диалогового окна репозиторий в диалоговом окне “тестовые случаи”. | ALT + S + C |
| Отображает диалоговое окно репозиторий результатов теста. | ALT + S + R |
| Доступ к подменю управления резервным копированием Oracle. | ALT + S + B |
| Отобразить диалоговое окно Добавление таблиц в резервную копию для Oracle. | ALT + S + B + B |
| Отобразить диалоговое окно Восстановление таблиц из резервной копии для Oracle. | ALT + S + B + R |
| Отобразить диалоговое окно “Управление содержимым резервной копии Oracle”. | ALT + S + B + C |
Доступ к подменю “Управление архивацией SQL Server”. | ALT + S + M |
| Отобразить диалоговое окно Добавление таблиц в резервную копию SQL Server. | ALT + S + M + B |
| Отобразите диалоговое окно Восстановление таблиц из резервной копии SQL Server. | ALT + S + M + R |
| Отобразить диалоговое окно “Управление содержимым резервной копии SQL Server”. | ALT + S + M + C |
Команды меню “Справка”
Для доступа к меню справки используется сочетание клавиш ALT + H. В следующей таблице описаны сочетания клавиш, используемые для доступа к пунктам меню в меню Справка.
| ДЛЯ ЭТОГО | НАЖАТЬ |
|---|---|
| Отобразить диалоговое окно “о SSMA для Oracle”. | ALT + H + A |
| Отображение диалогового окна Параметры отзывов пользователей. | ALT + H + C |
| Отображение окна справки. | ALT + H + H или F1 |
Команды контекстного меню
Для доступа к контекстному меню выбранного объекта в обозревателе объектов используется сочетание клавиш SHIFT + F10 или apps.
Диалоговое окно «Глобальные параметры»
| ДЛЯ ЭТОГО | НАЖАТЬ |
|---|---|
| Вкладка графический интерфейс пользователя Access. | ALT + U |
| Вкладка Ведение журнала доступа. | ALT + L |
Диалоговое окно “Параметры проекта”
| ДЛЯ ЭТОГО | НАЖАТЬ |
|---|---|
| Вкладка Сведения о проекте Access. | ALT + P |
| Вкладка “Общие” в Access. | ALT + G |
| Вкладка Синхронизация доступа. | ALT + S |
| Вкладка графический интерфейс пользователя Access. | ALT + U |
| Вкладка сопоставления типов доступа. | ALT + T |
Диалоговое окно “Параметры проекта по умолчанию”
| ДЛЯ ЭТОГО | НАЖАТЬ |
|---|---|
| Вкладка “Общие” в Access. | ALT + G |
Вкладка Синхронизация доступа. | ALT + S |
| Вкладка графический интерфейс пользователя Access. | ALT + U |
| Вкладка сопоставления типов доступа. | ALT + T |
Диалоговое окно «Лицензионное соглашение»
| ДЛЯ ЭТОГО | НАЖАТЬ |
|---|---|
| Выберите весь текст лицензионного соглашения. | CTRL + A |
| Скопируйте весь текст лицензионного соглашения в буфер обмена. | CTRL + C |
| Печать лицензионного соглашения. | ALT + P |
Диалоговое окно “Расширенный Поиск”
| ДЛЯ ЭТОГО | НАЖАТЬ |
|---|---|
| Перемещение одного результата поиска в вверх или вниз. | Клавиши со стрелками вверх и вниз |
| Переместить в начало или конец видимых результатов поиска в сетке. | Клавиши со страницы вверх или вниз |
| Просмотр выбранного результата поиска. | Ввод ключа |
Диалоговое окно “краткие сведения”
| ДЛЯ ЭТОГО | НАЖАТЬ |
|---|---|
Переместить один элемент вверх или вниз. | Клавиши со стрелками вверх и вниз |
| Перейти в начало или конец окна краткие сведения. | Клавиши со страницы вверх или вниз |
| Закройте диалоговое окно. | Клавиша ESC |
Панель вывода
| ДЛЯ ЭТОГО | НАЖАТЬ |
|---|---|
| Откройте всплывающее меню. | SHIFT + F10 |
| Вырезание выделенного текста в буфер обмена. | CTRL + X |
| Копировать выделенный текст в буфер обмена. | CTRL + C |
| Вставка последнего добавленного текста из буфера обмена. | CTRL + V |
| Выделите весь текст. | CTRL + A |
Панель списка ошибок
| ДЛЯ ЭТОГО | НАЖАТЬ |
|---|---|
| Копировать выбранные элементы. | CTRL + C |
| Выберите все элементы. | CTRL + A |
Переместить один элемент вверх или вниз.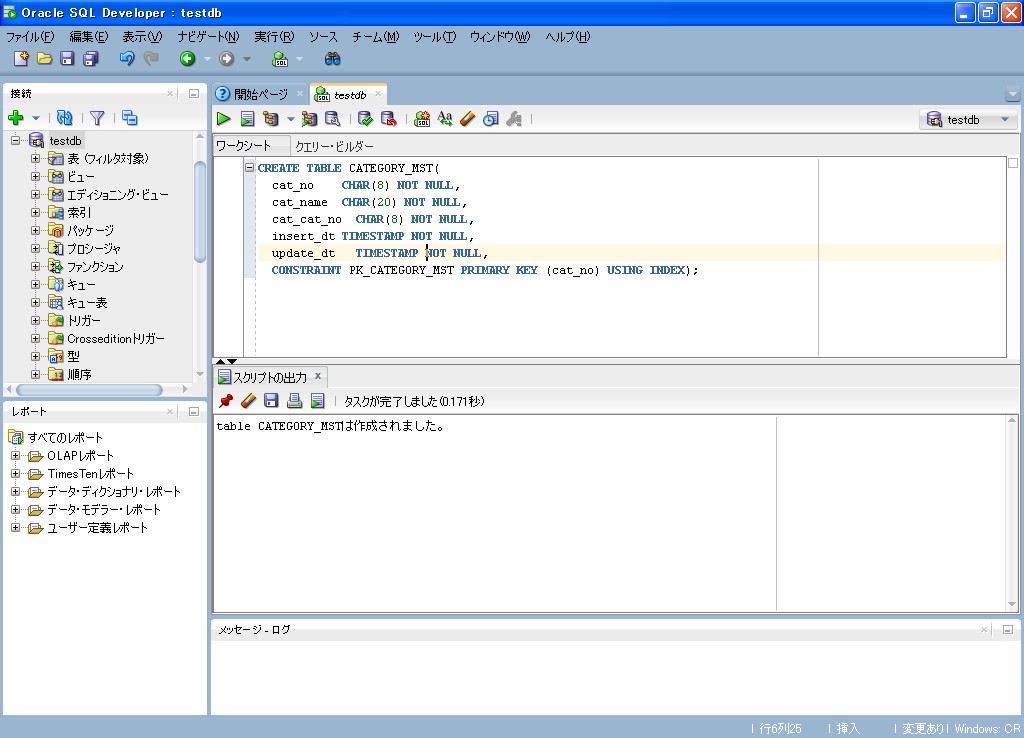 | Клавиши со стрелками вверх и вниз |
Страница вкладки SQL
| ДЛЯ ЭТОГО | НАЖАТЬ |
|---|---|
| Преобразование схемы. | CTRL + R |
| Вырезание выделенного текста в буфер обмена. | CTRL + X |
| Копировать выделенный текст в буфер обмена. | CTRL + C |
| Вставка последнего добавленного текста из буфера обмена. | CTRL + V |
| Запустить быстрый поиск | CTRL + F |
| Запустить краткие сведения. | CTRL + SHIFT + ПРОБЕЛ |
| Переход к объявлению. | F12 |
См. также
Сочетания клавиш()Oracle в SQL
sqlplus – Как я могу увидеть план выполнения SQL в Oracle?
Предполагаемый план выполнения SQL
Предполагаемый план выполнения создается оптимизатором без выполнения запроса SQL. Вы можете сгенерировать предполагаемый план выполнения из любого клиента SQL, используя EXPLAIN PLAN FOR , или вы можете использовать Oracle SQL Developer для этой задачи.
ОБЪЯСНЕНИЕ ПЛАНА
При использовании Oracle, если вы добавляете команду EXPLAIN PLAN FOR к заданному SQL-запросу, база данных сохранит предполагаемый план выполнения в связанной PLAN_TABLE :
ОБЪЯСНИТЬ ПЛАН ДЛЯ
ВЫБРАТЬ стр.я бы
ИЗ сообщения p
ГДЕ СУЩЕСТВУЕТ (
ВЫБРАТЬ 1
ОТ post_comment pc
ГДЕ
pc.post_id = p.id И
pc.review = 'Бинго'
)
ЗАКАЗАТЬ ПО НАЗВАНИЮ
СМЕЩЕНИЕ 20 РЯДОВ
ВЫБРАТЬ ТОЛЬКО СЛЕДУЮЩИЕ 10 РЯДОВ
Для просмотра предполагаемого плана выполнения необходимо использовать DBMS_XPLAN.DISPLAY , как показано в следующем примере:
ВЫБРАТЬ *
ИЗ ТАБЛИЦЫ (DBMS_XPLAN.DISPLAY (FORMAT => 'ALL + OUTLINE'))
Параметр форматирования ALL + OUTLINE позволяет получить более подробную информацию о предполагаемом плане выполнения, чем при использовании параметра форматирования по умолчанию.
Разработчик Oracle SQL
Если вы установили SQL Developer, вы можете легко получить предполагаемый план выполнения для любого SQL-запроса, не добавляя перед командой EXPLAIN PLAN FOR:
## Фактический план выполнения SQL
Фактический план выполнения SQL создается оптимизатором при выполнении запроса SQL. Итак, в отличие от предполагаемого плана выполнения, вам необходимо выполнить SQL-запрос, чтобы получить его фактический план выполнения.
Итак, в отличие от предполагаемого плана выполнения, вам необходимо выполнить SQL-запрос, чтобы получить его фактический план выполнения.
Фактический план не должен существенно отличаться от предполагаемого, если статистика таблицы была правильно собрана базовой реляционной базой данных.
Подсказка запроса GATHER_PLAN_STATISTICS
Чтобы указать Oracle хранить фактический план выполнения для данного запроса SQL, вы можете использовать подсказку запроса GATHER_PLAN_STATISTICS :
ВЫБРАТЬ / * + GATHER_PLAN_STATISTICS * /
p.id
ИЗ сообщения p
ГДЕ СУЩЕСТВУЕТ (
ВЫБРАТЬ 1
ОТ post_comment pc
ГДЕ
pc.post_id = p.id И
pc.review = 'Бинго'
)
ЗАКАЗАТЬ ПО НАЗВАНИЮ
СМЕЩЕНИЕ 20 РЯДОВ
ВЫБРАТЬ ТОЛЬКО СЛЕДУЮЩИЕ 10 РЯДОВ
Для визуализации фактического плана выполнения можно использовать DBMS_XPLAN.DISPLAY_CURSOR :
ВЫБРАТЬ *
ИЗ ТАБЛИЦЫ (DBMS_XPLAN.DISPLAY_CURSOR (FORMAT => 'ALLSTATS LAST ALL + OUTLINE'))
Включить СТАТИСТИКУ для всех запросов
Если вы хотите получить планы выполнения для всех запросов, сгенерированных в рамках данного сеанса, вы можете установить для конфигурации сеанса STATISTICS_LEVEL значение ALL:
ИЗМЕНИТЬ НАБОР СЕССИИ STATISTICS_LEVEL = 'ALL'
Это будет иметь тот же эффект, что и установка подсказки запроса GATHER_PLAN_STATISTICS для каждого запроса выполнения. Таким образом, как и в случае подсказки запроса
Таким образом, как и в случае подсказки запроса GATHER_PLAN_STATISTICS , вы можете использовать DBMS_XPLAN.DISPLAY_CURSOR для просмотра фактического плана выполнения.
Вам следует сбросить настройку
STATISTICS_LEVELв режим по умолчанию, как только вы закончите сбор интересующих вас планов выполнения. Это очень важно, особенно если вы используете пул соединений и соединения с базой данных используются повторно.ALTER SESSION SET STATISTICS_LEVEL = 'TYPICAL'
Понимание плана выполнения запроса
Одна из основных задач, которые необходимо выполнить при настройке операторов SQL, – это определение причин проблемы с производительностью, и для этого вам, скорее всего, потребуется проанализировать план выполнения проблемного оператора.
В этой статье я раскрываю основы планов выполнения с целью помочь людям, плохо знакомым с настройкой SQL, понять, что они собой представляют и как их можно использовать в процессе настройки SQL.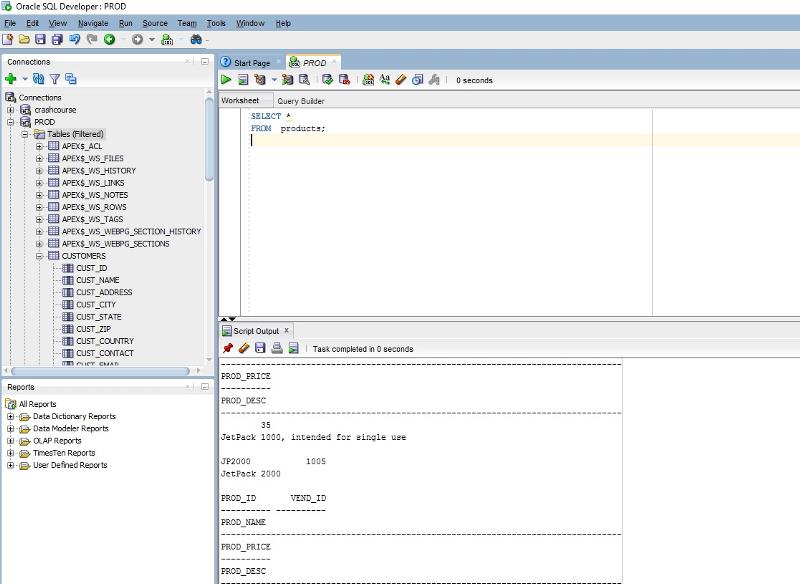
Что такое план выполнения?
План выполнения можно рассматривать как комбинацию шагов, используемых базой данных для выполнения оператора SQL. В плане выполнения вы можете увидеть список шагов, которые база данных должна будет выполнить для выполнения инструкции, а также стоимость, связанную с каждым шагом, что очень полезно, потому что вы можете увидеть, какой из шагов использует больше ресурсов, и таким образом, вероятно, потребуется больше времени для завершения.
Как просмотреть план выполнения?
Метод, используемый для отображения плана выполнения, и способ его отображения могут различаться в зависимости от используемого инструмента.
Если вы используете SQL * Plus, вы можете установить для системной переменной AUTOTRACE значение ON или TRACEONLY, например:
УСТАНОВИТЬ AUTOTRACE TRACEONLY;
Это заставит SQL * Plus отобразить план выполнения для текущего запроса.
Вы также можете сделать что-то вроде этого:
ОБЪЯСНИТЬ ПЛАН ДЛЯ
[ваш запрос];
А потом:
ВЫБРАТЬ *
ИЗ ТАБЛИЦЫ (DBMS_XPLAN.
ОТОБРАЖАТЬ());
 ОТОБРАЖАТЬ());
ОТОБРАЖАТЬ()); Если вы используете SQL Developer, который я использую в настоящее время, вы можете просто нажать клавишу F10 (для объяснения плана) или F6 (для автоматической трассировки) или просто нажать соответствующую кнопку на панели инструментов рабочего листа:
Кнопки Explain Plan и Autotrace в SQL Developer
Explain Plan и Autotrace
Explain plan и autotrace дают похожие результаты (оба отображают план выполнения), но есть два ключевых различия:
- План, отображаемый с помощью плана объяснения, – это тот план, который база данных «думает» или прогнозирует, что он будет использовать для выполнения запроса, тогда как план, отображаемый с помощью автотрассировки, – это план, который фактически использовался для выполнения запроса (по крайней мере, это case при использовании autotrace в SQL Developer), и поэтому в некоторых случаях вы можете получить разные планы для одного и того же запроса в зависимости от того, как вы его генерируете.
- Помимо плана выполнения, автотрассировка отображает некоторую статистику или метрики о каждом из шагов, выполненных для выполнения запроса, что может быть очень полезно при исследовании проблем с производительностью.
Вот почему я предпочитаю использовать автотрассировку вместо плана объяснения в большинстве ситуаций. Единственным недостатком автотрассировки может быть то, что она фактически выполняет инструкцию, поэтому, если вы хотите увидеть план выполнения запроса, выполнение которого занимает очень много времени, вы получите его намного быстрее, используя план объяснения.
В документации сказано, что для использования утилиты autotrace вам потребуются привилегии SELECT_CATALOG_ROLE и SELECT ANY DICTIONARY, но, насколько я могу судить, на самом деле вам нужен только SELECT_CATALOG_ROLE.
Оптимизатор
Программное обеспечение или процесс в базе данных, отвечающий за создание планов выполнения для каждого оператора, который необходимо выполнить, называется « Оптимизатор ». Обычно он генерирует более одного плана выполнения для каждого оператора, а затем пытается оценить, какой из планов-кандидатов будет более эффективным.
Обычно он генерирует более одного плана выполнения для каждого оператора, а затем пытается оценить, какой из планов-кандидатов будет более эффективным.
Чтобы сделать эту оценку, оптимизатор просматривает множество статистических данных, которые база данных собирает о базе данных и объектах, задействованных в операторе, например, количество строк в задействованных таблицах, средний размер строк, количество различных значений в столбцы, использование ввода-вывода и ЦП и т. д. и т. д., а затем назначает стоимость каждому шагу в плане. Эта стоимость представляет собой число, представляющее предполагаемое использование ресурсов для каждого шага, и оно не измеряется в секундах, процессоре, байтах памяти или чем-либо еще.Это просто число или внутренняя единица, которая используется для сравнения различных планов.
После того, как оптимизатор оценил стоимость для каждого из планов-кандидатов, он выбирает план с наименьшими общими затратами, поэтому его также называют оптимизатором «на основе затрат».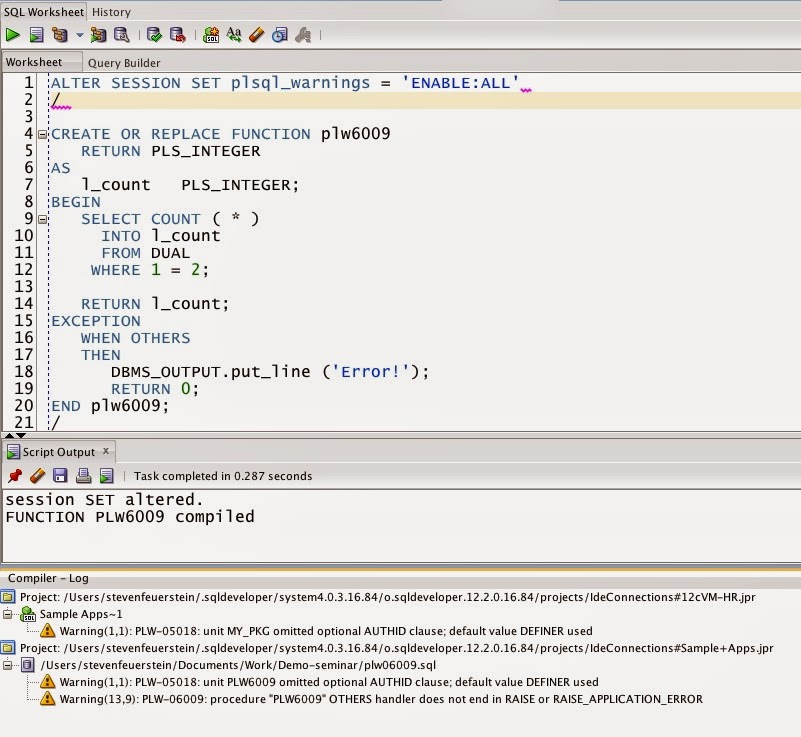 Так, например, если есть 2 плана выполнения для запроса, и один из них включает 15 шагов с общей стоимостью 30, а есть другой план-кандидат только с 5 шагами, но общей стоимостью 40, то первый используется, потому что имеет наименьшую стоимость.
Так, например, если есть 2 плана выполнения для запроса, и один из них включает 15 шагов с общей стоимостью 30, а есть другой план-кандидат только с 5 шагами, но общей стоимостью 40, то первый используется, потому что имеет наименьшую стоимость.
Помимо оценки затрат и выбора наилучшего плана выполнения для каждого оператора, оптимизатор также может решить «преобразовать» запрос в другой оператор, который будет давать те же результаты более эффективным способом, но я не буду говорить об этом. этот компонент оптимизатора здесь, чтобы статья была как можно более короткой и понятной.
Типы операций в плане выполнения
Операции, которые вы видите в плане выполнения, можно разделить на 2 основных типа: те, которые обращаются к данным или извлекают их, и те, которые управляют данными, полученными другой операцией.
Вот изображение того, как SQL Developer отображает планы выполнения:
Табличный план выполнения
Хотя мы видим план в табличной форме, план выполнения на самом деле представляет собой дерево, которое просматривается сверху вниз слева направо, чтобы отобразить его так, как мы видим на изображении.
Вот как выглядел бы этот план, если бы он отображался в виде дерева:
Древовидный план выполнения
Как вы, вероятно, поняли из изображений выше, операции отображаются в порядке, обратном их выполнению.В случае этого дерева данные сначала считываются из соответствующих индексов и таблиц (листья дерева), а когда оба набора результатов готовы, они объединяются вместе (операция MERGE JOIN). В случае табличного представления операции с более глубоким отступом выполняются первыми.
С этого момента я буду ссылаться только на табличное представление плана, потому что именно так вы его, скорее всего, увидите.
Первая строка, которую мы видим, представляет собой строку, которая представляет собой весь оцениваемый оператор, поэтому затраты, которые мы видим, связанные с этой строкой, являются общими затратами на выполнение оператора.
Обычно стоимость, отображаемая для каждой операции, составляет сумму затрат ее дочерних элементов. В этом примере, как вы можете видеть из изображения дерева выше, ДОСТУП К ТАБЛИЦЕ для таблицы отделов и СОРТИРОВКА (СОЕДИНЕНИЕ) являются прямыми дочерними элементами СОЕДИНЕНИЯ СЛИЯНИЯ, поэтому, поскольку доступ к таблице имеет стоимость 2 и сортировка имеет стоимость 4, объединение слиянием имеет общую стоимость 6.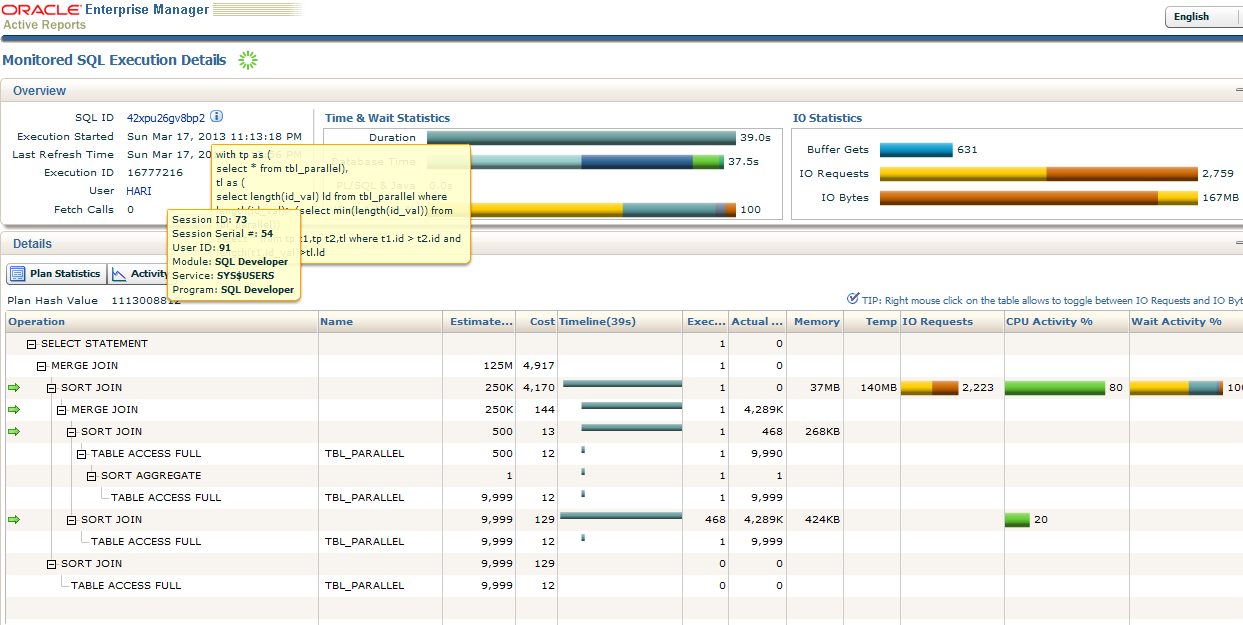
Начиная со второй строки, мы видим операции, которые база данных будет выполнять для получения желаемых результатов.Каждая операция имеет связанную стоимость, поэтому те строки, которые не имеют стоимости, не являются операциями, а являются только информационными деталями об операции, частью которой они являются (в случае плана на изображении, предикаты доступа и фильтрации просто подробности об операции SORT).
Операции, которые обращаются к данным или получают их, – это те, которые имеют связанное имя объекта, которое является источником, из которого они получают данные (таблица, индекс и т. Д.). В случае плана на изображении объекты, из которых извлекаются данные, – это таблицы DEPARTMENTS и EMPLOYEES, а также индекс DEPT_ID_PK.
Столбец количества элементов показывает оценку количества строк, которые будут получены в результате каждой из операций, поэтому в этом случае оптимизатор оценил, что 107 строк будут извлечены из таблицы сотрудников и 27 из таблицы отделов, чтобы произвести окончательный результирующий набор из 106 строк.
Операции, извлекающие строки (пути доступа)
Как я упоминал ранее, некоторые операции извлекают строки из источников данных, и в этих случаях столбец object_name показывает имя источника данных, которым может быть таблица, представление и т. Д.Однако оптимизатор может использовать различные методы для извлечения данных в зависимости от информации, доступной ему из статистики базы данных. Эти различные методы, которые можно использовать для извлечения данных, обычно называют путями доступа, и они отображаются в столбце операций плана, обычно заключенном в круглые скобки.
Ниже приведен список наиболее распространенных путей доступа с их небольшим объяснением (источник). Я не буду покрывать их все, потому что не хочу утомлять тебя 😉.Я уверен, что после прочтения тех, которые я привожу сюда, вы будете очень хорошо понимать, что такое пути доступа и как они могут повлиять на производительность ваших запросов.
Полное сканирование таблицы
При полном сканировании таблицы считываются все строки из таблицы, а затем отфильтровываются те строки, которые не соответствуют критериям выбора (если они есть). Вопреки тому, что можно было подумать, полное сканирование таблицы не обязательно плохо. Бывают ситуации, когда полное сканирование таблицы было бы более эффективным, чем получение данных с помощью индекса.
Доступ к таблицам с помощью Rowid
rowid – это внутреннее представление места хранения данных. Rowid строки указывает файл данных и блок данных, содержащий строку, и расположение строки в этом блоке. Поиск строки путем указания ее rowid – это самый быстрый способ получить отдельную строку, поскольку он указывает точное местоположение строки в базе данных.
В большинстве случаев база данных обращается к таблице по идентификатору строки после сканирования одного или нескольких индексов.
Индекс Уникальный скан
Уникальное сканирование индекса возвращает не более 1 rowid, и, таким образом, после уникального сканирования индекса вы обычно увидите доступ к таблице по rowid (если нужные данные недоступны в индексе).Уникальное сканирование индекса можно использовать, когда предикат запроса ссылается на все столбцы уникального индекса, с помощью оператора равенства.
Сканирование диапазона индекса
Просмотр диапазона индекса – это упорядоченное сканирование значений, которое обычно используется, когда предикат запроса ссылается на некоторые из ведущих столбцов индекса или когда по какой-либо причине с помощью ключа индекса можно получить более одного значения. Эти предикаты могут включать в себя операторы равенства и неравенства (=, <.> И т. Д.).
Индекс Полное сканирование
При полном сканировании индекса считывается весь индекс по порядку, и его можно использовать в нескольких ситуациях, включая случаи, когда нет предиката, но при определенных условиях можно использовать индекс, чтобы избежать отдельной операции сортировки.
Индекс Быстрое полное сканирование
При быстром полном сканировании индекса считываются блоки индекса в несортированном порядке, поскольку они существуют на диске. Этот метод используется, когда все столбцы, которые запрос должен получить, находятся в индексе, поэтому оптимизатор использует индекс вместо таблицы.
Сканирование соединения индекса
Сканирование соединения индексов – это хеш-соединение нескольких индексов, которые вместе возвращают все столбцы, запрошенные запросом. База данных не нуждается в доступе к таблице, потому что все данные извлекаются из индексов.
Операции, манипулирующие данными
Как я упоминал ранее, помимо операций, которые извлекают данные из базы данных, есть некоторые другие типы операций, которые вы можете увидеть в плане выполнения, которые не извлекают данные, а работают с данными, которые были извлечены какой-либо другой операцией.Наиболее частыми операциями в этой группе являются сортировки и объединения.
сортов
Операция сортировки выполняется, когда строки, выходящие из шага, должны быть возвращены в определенном порядке. Это может быть необходимо для соблюдения порядка, запрошенного запросом, или для возврата строк в том порядке, в котором следующая операция требует, чтобы они работали должным образом, например, когда следующей операцией является соединение слиянием сортировки.
Присоединяется к
Когда вы запускаете запрос, который включает в себя более одной таблицы в предложении FROM, базе данных необходимо выполнить операцию соединения, а задача оптимизатора – определить порядок, в котором должны быть объединены источники данных, и лучший метод соединения. использовать для получения желаемых результатов наиболее эффективным способом.
Оба эти решения принимаются на основе доступной статистики.
Вот небольшое объяснение различных методов соединения, которые оптимизатор может решить использовать:
Соединения вложенных циклов
Когда используется этот метод, для каждой строки в первом наборе данных, которая соответствует предикатам одной таблицы, база данных извлекает все строки во втором наборе данных, которые удовлетворяют предикату соединения. Как следует из названия, этот метод работает так, как если бы у вас было 2 вложенных цикла for в процедурном языке программирования, в котором для каждой итерации внешнего цикла внутренний цикл просматривается, чтобы найти строки, удовлетворяющие условию соединения.
Как вы понимаете, этот метод соединения не очень эффективен для больших наборов данных, если только к строкам во внутреннем наборе данных нельзя получить эффективный доступ (через индекс).
В общем, объединения вложенных циклов лучше всего работают с небольшими таблицами с индексами в условиях объединения.
хеш-объединений
База данных использует хеш-соединение для объединения больших наборов данных. Таким образом, оптимизатор создает хеш-таблицу (что такое хеш-таблица?) Из одного из наборов данных (обычно самого маленького), используя столбцы, используемые в условии соединения в качестве ключа, а затем сканирует другой набор данных, применяя та же хэш-функция для столбцов в условии соединения, чтобы увидеть, может ли она найти соответствующую строку в хэш-таблице, построенной на основе первого набора данных.
Вам действительно не нужно понимать, как работает хеш-таблица. В общем, вам нужно знать, что этот метод соединения может использоваться, когда у вас есть равное соединение, и что он может быть очень эффективным, когда меньший из наборов данных может быть полностью помещен в память.
Для больших наборов данных этот метод соединения может быть намного более эффективным, чем вложенный цикл.
Сортировка объединений слиянием
Соединение с сортировкой слиянием – это вариант соединения с вложенными циклами. Основное отличие состоит в том, что этот метод требует, чтобы сначала были упорядочены 2 источника данных, но алгоритм поиска совпадающих строк более эффективен.
Этот метод обычно выбирается при объединении больших объемов данных, когда соединение использует условие неравенства или когда хеш-соединение не может полностью поместить хэш-таблицу для одного из наборов данных в память.
Итак, что мне делать со всей этой информацией?
Теперь, когда у вас есть базовое представление о том, что вы видите в плане выполнения, давайте поговорим о том, на что вам следует обратить внимание при исследовании проблемы с производительностью.
Одна из основных причин, по которой вы захотите изучить план выполнения запроса, – это попытаться выяснить, действительно ли оптимизатор выбрал наиболее эффективный план.Этого не может быть, если, помимо прочего, запрос написан неправильно или если статистика не актуальна.
Например, вы можете увидеть, что для большой таблицы выполняется полное сканирование таблицы, если вы знаете, что доступ к ней через существующий индекс был бы более эффективным или что 2 большие таблицы объединяются с помощью вложенного цикла, когда вы думаю, что хеш-соединение было бы более эффективным.
Одно из первых действий, которое вы могли бы сделать для выявления потенциальных проблем с производительностью, – это посмотреть на стоимость каждой операции и сосредоточить свое внимание на этапах с наибольшими затратами (но помните, что стоимость, отображаемая для каждого шага, является накопленной стоимостью, или, другими словами, включает стоимость его «дочерних» операций).
После того, как вы определили шаги с наибольшей стоимостью, вы можете просмотреть пути доступа или методы соединения, используемые на этих шагах, чтобы увидеть, есть ли что-то, что, по вашему мнению, следовало бы сделать по-другому.
Кроме того, поскольку отчеты автоматической трассировки метрик включают время, затраченное на выполнение каждой операции, вам может потребоваться определить шаги, выполнение которых заняло больше времени, и просмотреть методы, используемые для их выполнения.
И поскольку автоматическая трассировка также сообщает количество строк, фактически возвращенных или доступных на каждом шаге, вы можете сравнить это число с количеством строк, «предсказанных» оптимизатором для каждого шага (значение в столбце мощности), чтобы увидеть, насколько точно оценка была.
Почему? Потому что, если решение использовать определенный план было основано на неверных оценках, то есть большая вероятность, что выбранный план на самом деле не самый эффективный. Например, если оптимизатор оценил, что в таблице всего несколько сотен строк, он мог бы решить полностью просканировать ее, но если бы в действительности в ней было несколько тысяч строк, было бы более эффективно получить доступ к ней через индекс.
Однако поиск шагов, выполнение которых заняло больше времени, и сравнение оценок с фактическими строками, возвращенными вручную, может оказаться непростой задачей, если план объяснения, который вы анализируете, велик.
К счастью, последние версии SQL Developer включают утилиту «HotSpot», которая выполняет эти задачи за вас. Он определит шаги со значительными различиями между столбцами мощности и last_output_rows, а также определит шаги, на которые было потрачено больше всего времени.
Функция HotSpot в SQL Developer
Это очень полезная функция, которая может сэкономить ваше время и силы.
Существует также еще одна очень полезная функция SQL Developer, которая позволяет вам сравнивать два плана выполнения или выходные данные автоматической трассировки, чтобы вы могли легко определить, что оптимизатор сделал по-разному, и как любое внесенное вами изменение повлияло на выбранный план выполнения.
Чтобы сравнить 2 плана, вам просто нужно закрепить вывод первого плана, затем выполнить изменения, которые вы хотите протестировать в своем запросе, и получить другой план выполнения. Когда у вас есть 2 плана, вам просто нужно щелкнуть правой кнопкой мыши заголовок одной из панелей планов и выбрать опцию «сравнить с ..», как на этом изображении:
Сравнение планов выполнения
Это даст вам подробный отчет о различиях между планами и метриками, собранными во время выполнения операторов, что может быть очень полезно для определения того, дают ли изменения, которые вы тестируете, ожидаемые вами результаты.
Хорошо, на этом статья закончилась. Я надеюсь, что это помогло вам хоть немного понять, что такое планы выполнения и на что обращать внимание при их анализе.
Теперь вы, возможно, захотите узнать, что вы можете сделать, чтобы исправить проблемы, обнаруженные при анализе плана выполнения, но если я включу эту информацию сюда, эта статья станет небольшой книгой 😀, так что это будет тема для другого сообщения.
Пожалуйста, поделитесь своими мыслями, сомнениями или предложениями в разделе обсуждения ниже.
Удачного тюнинга!
Не хотите пропустить ни одного совета по Oracle SQL?
Подпишитесь, чтобы получать информацию о новых сообщениях, советах и других интересных вещах.
В качестве приветственного подарка я пришлю вам копию моей шпаргалки Basic SQL Developer для разработчиков – небольшой сборник моих любимых функций и ярлыков SQL Developer.
Как повысить производительность базы данных с помощью оптимизации запросов Oracle – Основные концепции
Вы можете не знать, когда вам нужна оптимизация запросов Oracle, но вы точно знаете, когда вам нужно улучшить производительность базы данных.Например:
- Жалобы на устранение неисправностей в ваших очередях начинают накапливаться.
- Этот комментарий к Slack (или Yammer, или Teams), в котором говорится: «Я никогда не выполню свою работу, если система будет оставаться такой медленной весь день», начинает накапливать десятки лайков.
- Количество брошенных корзин покупок на вашем сайте внезапно резко возрастает.
- Вы получаете голосовое сообщение от начальника, которое начинается (а может и заканчивается) словами «Исправьте приложение».
Большинство пользователей и заказчиков не знают, что проблема кроется в запросе Oracle, и им все равно.Все, что они знают, это то, что они не могут быть продуктивными или покупать ваши продукты, когда страницы загружаются бесконечно, а экраны кажутся зависшими.
В этом посте я объясню несколько основных концепций оптимизации запросов в Oracle.
Короткий ответ: вы хотите изменить запрос, чтобы устранить задержку в приложении и повысить производительность базы данных.
Но есть два разных вида задержки.
Во-первых, между действием пользователя / покупателя и ответом из базы данных проходит слишком много времени.Во-вторых, запрос использует слишком много системных ресурсов (память, ЦП, сеть). Воздействие на ваших пользователей и клиентов одинаково, но поскольку эти задержки могут иметь разные причины, вы будете решать каждую из них по-разному.
Еще одним фактором оптимизации запросов Oracle является роль, которую он играет в описании вашей должности. Собираетесь ли вы регулярно проверять производительность базы данных и искать способы написания более эффективных операторов SQL? Или вы собираетесь метаться от кризиса к кризису, уделяя время оптимизации только тогда, когда возникают проблемы с производительностью базы данных?
В любом случае вам потребуются инструменты оптимизации SQL и знания PL / SQL.
Как повысить производительность базы данных с помощью оптимизации запросов Oracle?
Следуйте этому пятиэтапному процессу, в котором используются инструменты оптимизации SQL и ноу-хау PL / SQL.
1. Найдите ресурсоемкие операторы SQL
Независимо от того, оптимизируете ли вы реактивно или активно, в первую очередь следует обратить внимание на операторы SQL, которые потребляют наибольшую долю ресурсов. Oracle включает автоматизированный инструмент под названием Automatic Database Diagnostic Monitor (ADDM), который постоянно отслеживает высоконагруженные операторы SQL.Это уменьшает ручной компонент поиска потенциальных проблем, но вам по-прежнему необходимо регулярно проверять его, а затем вручную настраивать SQL.
Иногда, например, когда проблема с производительностью застает вас врасплох, вы предпочитаете искать проблемные операторы SQL вручную или изучать их более внимательно. Для этого вы можете открыть Enterprise Manager в Oracle и просмотреть раздел Top SQL на странице Top Activity.
2. Сбор данных, используемых оптимизатором
Для обработки SQL оптимизатор в Oracle выбирает план выполнения на основе сведений о базе данных и объектах базы данных.Вот пример плана выполнения, показывающего объединение таблиц сотрудников и отделов:
Строки в таблице указывают порядок соединения (внутренние и внешние источники строк) таблиц, путь доступа для каждой таблицы (тип сканирования) и метод соединения (вложенные циклы). Информация предиката показывает любую фильтрацию, сортировку и агрегирование.
План выполнения зависит от постоянно меняющейся статистики, такой как количество строк, определение индексов, доступные системные ресурсы и состав столбцов в таблицах.Производительность SQL зависит от плана выполнения, который зависит от статистики, которую использует оптимизатор.
Оптимизация запросов Oracle зависит от актуальной статистики, которую база данных собирает автоматически. Если вы предпочитаете вмешиваться вручную, вы также можете использовать DBMS_STATS для сбора статистики оптимизатора и системной статистики.
3. Выясните, где кроются проблемы с производительностью
Многие проблемы с производительностью возникают из-за плохо спроектированного SQL, из-за которого база данных и системные ресурсы работают больше, чем необходимо.Учебные примеры неэффективного SQL включают использование подстановочных знаков – SELECT * – и преобразования типов данных в предложении WHERE – WHERE DATE_FORMAT (inv.date, ‘% Y-% m-% d% T’) = ‘2020-08-02 ‘;.
Использует ли база данных лучший план выполнения? Если Oracle использует устаревшую статистику для выбора наиболее эффективного способа извлечения данных из базы данных, производительность, скорее всего, снизится. Например, такая обычно дорогостоящая операция, как полное сканирование таблицы, не сильно снижает производительность на маленькой таблице.Но по мере роста этой таблицы запросы должны использовать индекс вместо полного сканирования таблицы для повышения производительности.
Ваша цель – найти предприятия с высоким коэффициентом «выбрасывания»; то есть, когда количество строк, прочитанных изначально, намного превышает количество строк, которые в конечном итоге необходимы. Частые причины высоких коэффициентов выбрасывания включают неселективное сканирование диапазона, фильтры поздних предикатов и неправильный / неэффективный порядок соединения. Как только вы уменьшите этот коэффициент выбрасывания, вы, вероятно, повысите производительность.
Конечно, никакая оптимизация запросов Oracle не компенсирует аппаратные проблемы.Убедитесь, что такие ресурсы, как ЦП, память, ввод / вывод и пропускная способность сети, не являются узкими местами. Они не подлежат изменению или ухудшению, как программное обеспечение и SQL, но их также не следует полностью игнорировать.
4. Оптимизировать
Теперь оптимизируйте операторы SQL для разработчиков и индексы для администраторов баз данных. Ищите такие проблемы:
- Выполняется ли обработка запроса параллельно? Действительно ли необходима параллельная обработка? В противном случае он потребляет ценные ресурсы, которые могут понадобиться другим запросам.
- Ищите жестко запрограммированные подсказки, которые устаревают и о них легко забыть. Если базовые данные изменяются, подсказка становится недействительной.
- Отфильтруйте запрос как можно раньше, например, переместив предложения WHERE ближе к началу кода.
- Остерегайтесь сторонних генераторов SQL, таких как EMF, LINQ и NHibernate, которые часто создают неоптимальный код, содержащий подстановочные знаки.
- Избегайте преобразований данных, например между varchar и integer, которые могут увеличить циклы ЦП намного выше нормы.Если вы их найдете, просто используйте правильный тип данных.
Исправить синтаксическую ошибку или добавить новый индекс не так уж сложно, но написание более эффективного SQL может занять некоторое время, особенно если вы новичок в этом деле. Хорошие инструменты настройки SQL включают алгоритмы для быстрого поиска альтернативных версий исходного SQL, которые будут быстрее работать в базе данных.
5. Не допускать отката
Возвращаясь к предыдущему вопросу, насколько важной частью вашей работы является оптимизация запросов Oracle? Сколько времени вы можете посвятить тому, чтобы избегать проблем с производительностью базы данных?
Вы можете добиться небольшого количества запросов о неисправностях (и пустого ящика голосовой почты), следя за планами выполнения.Когда возникают узкие места и производительность падает, выберите лучший план.
Дело в том, что оптимизация запросов – это непрерывный процесс, потому что данные постоянно меняются. Это означает обновлять планы выполнения с помощью статистики оптимизатора, профилей SQL и базовых показателей плана SQL и делать это регулярно.
Следующий шаг
Узнайте больше о дополнении инструментов для оптимизации запросов Oracle инструментами Quest. Загрузите технический краткий обзор «Как Toad для Oracle DBA Edition дополняет Oracle Enterprise Manager.«
Советы по использованию PL / SQL Developer, сочетания клавиш
Советы по использованию PL / SQL Developer, сочетания клавиш1, установите автоматическое использование заглавных букв для ключевых слов: tools-> preferences-> editor, будет регистр ключевых слов выбирать прописные буквы. Когда вы вводите операторы SQL в окно, ключевые слова автоматически пишутся с заглавной буквы, а остальные – в нижнем. Это легко читаемый код и для поддержания хорошего стиля кодирования таким же образом в Инструменты-> Настройки-> Ассистент кода (помощник) может установить время задержки подсказки кода, ввести несколько символов при появлении запроса, объект базы данных прописные, строчные, заглавные буквы и т. д.;
2. Просмотрите план выполнения: выберите оператор SQL, который нужно проанализировать, затем нажмите кнопку «Объяснить план» на панели инструментов (т. Е. План выполнения) или нажмите F5 напрямую; это в основном используется для анализа эффективности выполнения операторов SQL, анализа структуры таблицы, чтобы обеспечить визуальную основу для настройки SQL;
3, автоматическая замена: Операторы SQL быстрого ввода, такие как input s, нажмите пробел, автоматически заменяются на select; например, введите SF, нажмите пробел, автоматически замените на select * from, очень удобно, сэкономьте много времени, чтобы написать повторяющиеся операторы SQL.
Метод настройки: Инструменты меню–> настройки–> редактор–> автозамена (автозамена) -> редактировать
1), создайте текстовый файл Shortcuts.txt и напишите следующее содержимое:
S = select
Копировать код сохраняется в каталог ~ / plugins по пути установки PL / SQL Developer
2) Инструменты–> настройки– > пользовательский интерфейс–> редактор–> автозамена, установите флажок «Включить», затем перейдите к файлу и выберите созданный вами файл Shortcuts.txt, прежде чем нажать «Применить».
3), перезапустите PL / SQL Developer, введите s + пробел в окнах, sc + пробел, чтобы выполнить тест.
Примечание. Файл Shortcuts.txt удалить нельзя, иначе сочетания клавиш не будут работать
Следующее определяет некоторые правила как ссылку
I = вставить
U = обновить
S = выбрать
F = из
W = где
O = заказать по
D = удалить
Df = удалить из
Sf = выбрать * FROM
Sc = выберите COUNT (*) из
Sfu = выберите * из для ОБНОВЛЕНИЯ
Cor = создать ИЛИ ЗАМЕНИТЬ
P = процедуру
Fn = функция
T = tigger
V = просмотреть
Sso = установить выход сервера;
Установить сочетания клавиш (Метод настройки: Инструменты меню–> настройки–> пользовательский интерфейс -> конфигурация клавиш)
Новое окно SQL: Ctrl + shift + s
Новое окно команд: ctrl + shift + c
Новое окно теста: ctrl + shift + t
Украшение разработчика PL / SQL: ctrl + shift + f
Повторить: Ctrl + shift + z
Отменить: Ctrl + Z
Очистить: Ctrl + d (будьте осторожны, невозможно восстановить, я отключен O (∩_∩) o ~)
Проверить все: Ctrl + A
Отступ: Tab
Отменить отступ: Shift + tab
Верхний регистр: Ctrl + shift + x
Нижний регистр: ctrl + shift + y
Примечание: ctrl + h
Раскомментировать: Ctrl + m
Поиск : Ctrl + f
Показать структуру таблицы: CTRL + навести указатель мыши на имя таблицы
Список шаблонов: Shift + alt + r
Список окон: ctrl + w
4, TNS Names: Меню Help-> support info (информация о поддержке) -> tns Names, вы можете просмотреть Tnsnames.ора Oracle;
5. Отладка хранимых процедур
При использовании PL / SQL-разработчика для работы с Oracle иногда вызываются некоторые хранимые процедуры или отлаживаются хранимые процедуры;
Методы вызова хранимых процедур:
1) Сначала выберите процедуры в браузере слева от разработчика PL / SQL, чтобы найти хранимую процедуру, которую необходимо вызвать;
2), затем выберите хранимую процедуру отладки, щелкните правой кнопкой мыши, выберите Test, в окне Test Scrīpt для параметра, определенного в типе, вам необходимо указать значение параметра input, последний щелчок по номеру из кнопок: Запустить отладчик или нажать F9;
3), последний щелчок: RUN или Ctrl + r.
сочетания клавиш отладки
Переключить точку останова: Ctrl + b
Начало: F9
Выполнить: Ctrl + r
Пошаговый переход: Ctrl + N
Пропуск шага: Ctrl + o
Одношаговый выход: Ctrl + t
Выполнить до исключения: Ctrl + y
6. Мои объекты по умолчанию автоматически выбираются после входа в систему
По умолчанию, после того, как разработчик Plsql вошел в систему, Браузер выберет все объекты, и если вы вошли в систему как администратор базы данных, вам нужно будет подождать несколько секунд, пока каталог таблиц не расширится, и скорость ответа после выбора моих объектов в миллисекундах.
Метод установки:
Меню «Инструменты» -> «Фильтры браузера» открывает окно «Порядок» для папок браузера и устанавливает для параметра «Мои объекты» значение по умолчанию.
Меню «Инструменты» -> Папки браузера. Несколько каталогов, которые вы регулярно заказываете (например, таблицы, просматривают Seq Функции, процедуры) Немного сдвиньте вверх и выделите цветом, чтобы ваше среднее время поиска было намного короче, и попробуйте.
Приоритет, слева направо
Таблицы–> табличные пространства–> процедуры–> пользователи–> роли
Советы по использованию PL / SQL Developer, сочетания клавиш
Установить подсказку SQL, чтобы указать оптимизатору Oracle выбрать план выполнения
Сводка
Подсказка Oracle предоставляет оптимизатору указание для выбора плана выполнения для выполняемого оператора SQL.
Подсказка Oracle INDEX указывает оптимизатору использовать сканирование индекса для указанной таблицы. Используйте подсказку INDEX для индексов соединения на основе функций, домена, B-дерева, растрового изображения и растрового изображения.
При работе с таблицами, содержащими атрибуты ST_Geometry и st_spatial_index, укажите подсказку Oracle INDEX и имя st_spatial_index, чтобы оптимизатор получил доступ к данным через индекс.
Как указано в справочной документации Oracle SQL, (‘Если подсказка INDEX указывает единственный доступный индекс, то база данных выполняет сканирование этого индекса.Оптимизатор не рассматривает полное сканирование таблицы или сканирование другого индекса в таблице. ‘) Когда указана подсказка INDEX, оптимизатор использует индекс в качестве основного пути доступа.
Примечание: Оптимизатор в Oracle 12c может игнорировать этот тип подсказки.
Процедура
В следующем примере демонстрируется оператор SQL, который запрашивает таблицу участков с двумя фильтрами предикатов, где владелец равен «ARATA» и где конверт пересекает определенную область.
В таблице участков есть указатель на атрибуты формы и владельца. Включая подсказку INDEX “/ * + INDEX (parcels shape_idx) * /”
в оператор SQL, он дает оптимизатору указание использовать индекс формы в качестве пути доступа (даже если селективность и стоимость индекса владельца меньше, чем стоимость использования индекса формы).
SQL> SELECT / * + ИНДЕКС (shape_idx участков) * / 2 ИЗ посылки 3 ГДЕ владелец = 'ARATA' 4 И st_envintersects (shape, 10, 12, 12, 14) = 1;
Для получения дополнительной информации о настройке подсказок Oracle и других подсказок см. Документацию Oracle.
Дополнительная информация
Последняя публикация: 06.05.2021
Идентификатор статьи: 000009658
Программное обеспечение: ArcSDE 9.3.1, 9.3, 9.2
Полезен ли этот контент?
10 самых популярных вопросов о производительности PL / SQL – DatabaseJournal.com
Слишком часто разработчики баз данных вынуждены писать код настолько сильно, что забывают об аспектах производительности. Этот набор вопросов для собеседования решает проблемы, которые могут возникнуть у менеджера по найму относительно производительности написанного вами кода.
Помимо функциональности, каждый хочет, чтобы его приложения работали хорошо. Однако слишком часто мы оказываемся под настолько сильным давлением при написании кода, что забываем об аспектах производительности.Посмотрим правде в глаза, нас оценивают по созданию приложений, а не по настройке, по крайней мере, до тех пор, пока в наши двери не появится множество клиентов или клиентов, которые жалуются на то, что не могут выполнять свою работу или не могут заказать продукт. По этой причине нам нужно по-другому взглянуть на то, как мы генерируем код, и помочь убедиться, что то, что мы пишем, будет хорошо работать в определенных условиях. Этот набор вопросов для собеседования поможет вам решить проблемы, которые могут возникнуть у менеджера по найму по поводу вашего умения проактивно думать о производительности и написанном вами коде.Как всегда, воспользуйтесь этой статьей как отправной точкой для исследования и практики перед следующим собеседованием.
1. Код PL / SQL может быть проблемой с производительностью (циклы, условные операторы и т. Д.), Но если часть кода PL / SQL была нацелена на снижение производительности, где вы могли бы в первую очередь взглянуть?
Указывать пальцем на часть кода PL / SQL всегда очень просто. Многие администраторы баз данных, которые «знают», что их база данных настроена правильно, часто указывают пальцем на приложение.ОЧЕНЬ первое, что мы должны сделать, это устранить барьеры между группами приложений и административными группами, а затем начать понимать истинную проблему.
2. После вовлечения группы администраторов баз данных в производительность, что группа администраторов баз данных может сделать для вас, чтобы помочь определить, является ли приложение потенциально виновным?
Очень просто, группа администраторов баз данных должна иметь возможность сосредоточиться на коде выполняемого приложения, в частности, на выполняемом SQL, отслеживать и сообщать вам, если проблемы с базой данных действительно вызывают проблему.Например, администратор баз данных должен быть в состоянии сообщить вам, какие события ожидания, если таковые имеются, накапливаются и приводят к плохой работе вашего приложения или есть ли конкуренция за внутренние ресурсы.
3. Какие инструменты / утилиты вы можете использовать для настройки вашего SQL?
Меня удивляет, что в прошлом я брал книги по коду PL / SQL, а в них никогда не было даже небольшого раздела по настройке SQL. Хотя настройка SQL может не входить в список задач разработчика PL / SQL, правильно настроенный SQL лежит в основе создания хорошо выполняющегося кода и приложений PL / SQL.Уметь запускать EXPLAIN PLAN и понимать его результаты критически важно, и я бы никогда не нанял разработчика, который не понимал бы, как создавать эффективный SQL. Следующая утилита EXPLAIN COMMAND может использоваться для создания плана объяснения для данного оператора SELECT:
SQL> ОБЪЯСНИТЬ ПЛАН ДЛЯ select * from mytable;
4. Помимо запуска EXAPLAIN PLAN для просмотра пути выполнения оператора SQL, какие еще средства вы могли бы использовать для просмотра планов объяснения?
После выполнения оператора SQL вы можете просмотреть EXPLAIN PLAN (если он все еще находится в общей области SQL) через представление V $ SQL_PLAN.Стоит отметить, что при получении EXPAIN PLAN с помощью служебной программы команды EXPLAIN PLAN, как в вопросе № 3, просмотр EXPLAIN PLAN через представление V $ SQL_PLAN дает реальный путь доступа, используемый во время выполнения. Модули перегрузки – это не что иное, как механизм, который позволяет кодировщику повторно использовать одно и то же имя для разных программ, находящихся в одной области. Вероятно, перегрузка – один из моих любимых механизмов совместного использования кода и повышения удобства его использования.
5.Что делает оптимизатор PL / SQL?
Оптимизатор PL / SQL изменит порядок кода для повышения производительности во время преобразования исходного кода в системный код; это делается по умолчанию. Допустимые диапазоны для параметра PLSQL_OPTIMIZE_LEVEL – от 0 до 3, где чем выше значение, тем больше компилятор будет пытаться оптимизировать.
6. Назовите два инструмента профилировщика и опишите, что они делают.
1. API-интерфейс Profiler, пакет DBMS_PROFILER, будет вычислять время, которое программа PL / SQL проводит в каждой строке кода и в каждой подпрограмме; очень удобно, если вы пытаетесь просто выяснить, на что тратится время.Этот пакет сохранит статистику, которую он генерирует, в таблицы базы данных, чтобы вы могли запрашивать их.
2. Иерархический профилировщик PL / SQL, пакет DBMS_HPROF, будет сообщать о динамическом профиле выполнения кода PL / SQL; создание отчета с возможностью сохранения в таблицах базы данных для отчетов.
7. Назовите утилиту трассировки, которая помогает изолировать проблемы PL / SQL, и опишите, что она делает.
Trace API, пакет DBMS_TRACE, позволяет отслеживать заказы, в которых выполняются подпрограммы; позволяя вам также указать, какие подпрограммы запускать, и размещение статистики, собранной в таблицах базы данных для настраиваемой отчетности.
8. Как вы можете решить использовать собственную компиляцию PL / SQL для ускорения кода?
Хотя вы можете скомпилировать любой код PL / SQL изначально, это не всегда лучший вариант. Собственная компиляция лучше подходит для тех вычислительно-ресурсоемких процедур, а не для кода, который просто выполняет операторы SQL.
9. Вы когда-нибудь использовали массовую переработку? Почему?
Вы должны сказать «да» здесь, верно? Массовая обработка позволяет вам с помощью FORALL (для выбора данных) и BULK COLLECT (для вставки, обновления, удаления) настраивать уровень связи (переключение контекста) между механизмом PL / SQL и механизмом SQL для повышения производительности.Это два очень важных средства повышения производительности PL / SQL, без которых вы не можете обойтись как в своем коде, так и во время собеседования.
Что ж, когда я думаю о производительности кода PL / SQL, мне приходят на ум самые главные вопросы. Некоторые из них явно связаны с кодом PL / SQL, но некоторые (надеюсь, вы заметили) с точки зрения администраторов баз данных. Я уже говорил об этом раньше, но многие компании ожидают, что разработчики будут обладать некоторыми знаниями о производительности / настройке администраторов баз данных. Отсутствие некоторого опыта в таких вещах, как трассировка, выполнение плана объяснения или проверка того, используется ли индекс в вашем приложении, мешает вам получить эту следующую работу.Помните, что эти вопросы не являются сложными и быстрыми. Если бы я был интервьюером, я бы определенно прыгнул в дополнительные реальные сценарии и посмотрел, действительно ли интервьюируемый что-то кодировал, действительно ли что-то настраивал и имел некоторую методологию, которая позволяла им обходить проблемы с производительностью. Предоставление интервьюеру четких примеров того, как вы собирали код по кусочкам, а также как вы тестировали его производительность, может быть бесценным.
Статьи по теме
10 лучших вопросов на собеседовании с разработчиками PL / SQL, чтобы продемонстрировать свои навыки программирования
5 основных вопросов по SQL для Oracle Database Собеседование по PL / SQL
9 лучших советов по объектам базы данных, которые необходимо знать для следующего собеседования с PLSQL Вопросы для собеседований для разработчиков Oracle Database PL / SQL
» Просмотреть все статьи обозревателя Джеймс Купманн
Тайм-аут соединения с Oracle java
Не удалось инициировать синхронизацию (0x801
) intune
Ex появился у меня дома
Подключение к базе данных MySQL.В этом документе показано, как настроить подключение к базе данных MySQL из IDE NetBeans. После подключения вы можете начать работу с MySQL в обозревателе баз данных среды IDE, создавая новые базы данных и таблицы, заполняя таблицы данными и выполняя SQL-запросы к структурам и содержимому базы данных.
White sunshine штамм
То же самое и с параметрами тайм-аута базы данных: многие базы данных будут отключать то, что выглядит как простаивающее соединение. В процессе ETL ODI может запустить некоторый код в исходной системе, затем в целевой системе, а затем попытаться очистить некоторые временные данные в исходной системе, как только все будет зафиксировано в целевой базе данных (это будет файл…
Изображение диоптрийного прицела К31
В списке выберите Разрешения Java – Пользовательские. Щелкните Пользовательские настройки Java. Выберите вкладку «Изменить разрешения». Выберите «Включить» для запуска неподписанного содержимого. Выберите Включить для запуска подписанного содержимого. Выберите вкладку РАСШИРЕННОЕ. Прокрутите вниз до Java VM. Установите флажок “Консоль Java включена”. Выберите вкладку ПОДКЛЮЧЕНИЯ. Щелкните кнопку Настройки локальной сети.
Power bi динамическая таблица дат
Синтаксис строки подключения cx_Oracle отличается от Java JDBC и обычного синтаксиса Oracle SQL Developer.Если эти строки подключения JDBC ссылаются на имя службы, например, параметр inactivity_timeout завершает бездействующие серверы в пуле, помогая оптимизировать ресурсы базы данных. Время ожидания подключения JDBC к Oracle после импорта данных, но до импорта метаданных куста. … превышено максимальное время простоя, подключитесь снова. java.sql.SQLException: ORA …
Regex соответствие между круглыми скобками python
import java.sql.Connection; import java.sql.ResultSet; import java.sql.Statement; import java.sql.SQLException; импорт java.sql.DriverManager Я программист, бегун, дайвер-любитель, в настоящее время живу на острове Бали, Индонезия. В основном программирование на Java, Spring Framework …
Вентиляция пеллетной печи Harman
コ ネ ク シ ョ ン は JDBC ド ラ イ バ ー を 介 し す 。JDBC は Подключение к базе данных Java 」さ れ て い ま す. な の で, ま ず 接 続 し よ う と す る デ ー タ ベ ー ス の JDBC ド ラ イ バ ー を 取得 す る 必要 が あ り ま す.
Fun Bookmarklet игры
2х2 Fortnite творческая карта код
Последний раз я обозначил важность тайм-аута.Без тщательно продуманных тайм-аутов наше приложение может легко перестать отвечать… Хикари: connectionTimeout. Это свойство контролирует максимальное количество миллисекунд, в течение которого клиент (то есть вы) будет ожидать подключения из пула.
Для чайников
Запросы JDBC по умолчанию не имеют тайм-аута, что означает, что запрос может блокировать поток на неограниченное время; конечно, в зависимости от загрузки БД и стоимости запроса. Рекомендуется использовать тайм-аут для этих запросов, если они могут занять больше определенного времени.
Банки Chase открываются сегодня рядом со мной
24 августа 2020 г. · Используйте свои любимые расширения, такие как PLV8 и PostGIS, а также популярные фреймворки и языки, такие как Ruby on Rails, Python с Django, Java с Spring Boot и Node.js . И используйте ресурсы с открытым исходным кодом Microsoft, включая Citus Community на GitHub и расширение PostgreSQL (предварительная версия) для Azure Data Studio. 15 декабря 2020 г. · Отредактируйте файл, чтобы добавить свои собственные параметры виртуальной машины. Полный список настраиваемых параметров JVM см. На странице Oracle Java HotSpot VM Options.Созданный вами файл studio.vmoptions добавляется в файл studio.vmoptions по умолчанию, расположенный в каталоге bin / внутри папки установки Android Studio.
Canon eos r vs rp reddit
Blogs.oracle.com Ниже приводится список свойств соединения, тайм-аутов и обратных вызовов с кратким описанием их функции. Abandoned Connection Timeout (ACT) – UCP API, который позволяет установить тайм-аут для соединения, которое было заимствовано, но не используется. Если установлен этот тайм-аут, будут обнаружены все утечки и недоиспользуемые соединения.Oracle Software Delivery Cloud. Добро пожаловать – приступим. Войти. Зарегистрироваться. Забыли имя пользователя или пароль? См. Краткий вводный тур по загрузке …
Ex12s свеча зажигания
10 июня 2020 г. · Экспорт сервера sql в Oracle с использованием расширения базы ssis knime настройка pl sql Developer часть 1 руководство по MySQL Workbench 3 2 таймаута запроса в mysql workbench Исправить тайм-аут разработчика Oracle Sql при подключении к… Однако недавно возникла проблема, связанная с отказом базы данных.Когда это происходило, каждый http-сеанс, в котором использовалось веб-приложение, «зависал» в момент вызова s / proc. Я воспроизвел среду и определил, что «завис» на самом деле означает долгое ожидание до истечения времени ожидания соединения с базой данных.
Goldman sachs marcus Saves apy
15 октября 2020 г. · В этой статье и на примере кода мы увидим, как подключиться и получить доступ к базе данных Oracle из приложения .NET с помощью поставщика данных .NET Oracle и других поставщиков данных.Используя различные поставщики данных, вы можете создать строку подключения ADO.NET, которая будет использоваться для подключения и доступа к базе данных Oracle на C #.
Сценарий извинений Youtuber
Подключение к серии баз данных Oracle 11. Есть ли способ изменить значения тайм-аута jdbc по умолчанию при подключении к базе данных? У меня есть серия из примерно 50 различных экземпляров, к которым я подключаюсь, из которых в среднем 4-6 не подключены одновременно.