Распознавание текста с картинки с китайского – Лучшие программы и онлайн сервисы для распознавания текста с картинки или фото
- Комментариев к записи Распознавание текста с картинки с китайского – Лучшие программы и онлайн сервисы для распознавания текста с картинки или фото нет
- Советы абитуриенту
Как распознать текст с картинки и сохранить его
Что делать, если надо распознать текст с картинки или сканированный текст, а подходящей программы на компьютере нет? Устанавливать специальный софт? Но это долго, и большинство их них платны.
i2OCR (Optical Character Recognition) – 100% бесплатный онлайн сервис, который быстро распознает текст с любого изображения и позволит скачать его в виде файла. В качестве источника можно использовать страницы книг, факсы, рецепты, фотографии, скриншоты и пр.
Основные возможности i2OCR
- Для распознавания можно загружать как сами документы с компьютера, так и указывать ссылки на них в интернет
- Форматы исходников: JPG, PNG, BMP, TIF, PBM, PGM, PPM
- Поддержка более 60 языков, среди которых есть английский, русский, украинский, японский, китайский и пр.
- Распознанный текст можно сохранить и скачать в форматах: Text (txt), Microsoft Word (doc), Adobe PDF (pdf), HTML
- Поддержка многоколоночной верстки
- Редактирование распознанного текста в Google Docs или его онлайн перевод при помощи переводчиков Google или Bing
Как видим, возможности для бесплатного сервиса более чем впечатляющие и вполне достаточны для обычных нужд. Теперь рассмотрим как именно распознать текст с картинки при помощи i2OCR.
Как работать с сервисом
Всё делается очень быстро в три простых этапа:
- Загрузка файла или указание ссылки на него в интернет
- Указание языка текста на картинке
- Нажатие кнопки «Extract Text»
Для проверки качества работы сервиса я выбрал следующие изображение со сканированным текстом (качество шрифта не самое лучшее):

Вот такой результат я получил в итоге:

Всё распознано идеально, без ошибок кроме символа «№».
После того как текст будет распознан, появятся кнопки дополнительных опций:
- «Download» — скачать документ в одном из форматов
- «Translate» — перевести на другой язык
- «Edit Google Docs» — внести правки в онлайн редакторе
Ограничения сервиса
Все ограничения сервиса носят лишь системный характер и состоят в следующем:
- размер загружаемого изображения не должен превышать 10 MB
- сервис не распознает рукописный текст
i2OCR не имеет ограничений на количество загружаемых файлов и на число скачиваний! Все возможности сервиса абсолютно бесплатны и доступны без регистрации!
Итог
При помощи сервиса i2OCR можно бесплатно распознать онлайн текст с картинки (скана, фото и пр.), сделать его перевод на другой язык, отредактировать, сохранить и скачать в одном из форматов (txt, doc, pdf, html). Всё делается быстро, четко и без установки на ПК дополнительных программ. Сервис однозначно должен быть в закладках у каждого!
P.S. Рекомендую также прочитать обзор двух лучших сервисов онлайн конвертирования речи в текст.
webtous.ru
Как распознать текст с фото и картинки онлайн
Как распознать текст с фото, этот вопрос задают многие пользователи. Причины разные, одна из причин — копирование текста с картинки, чтобы не переписывать его вручную. Иногда нам нужно перевести текст с картинки с иностранного языка. Для чтения текста с картинок существуют специальные сервисы и программы в Интернете, которые способны сделать просмотр фото с текстом. Именно их, мы и будем применять для этого дела в этой статье.
Распознать текст онлайн с картинки в Гугл Диск
Здравствуйте друзья! Распознать текст онлайн с картинки, можно в Гугл Диске. Гугл диск, это сервис по хранению файлов в Интернете, но он так, же имеет много преимуществ. И одно преимущество – это распознавание текста онлайн. Как это делается? Открывайте любой браузер и пишите в нём — Googl Диск. Заходите на этот сайт. Переходите туда, и нажмите на функцию создать, чтобы загрузить файл для точного просмотра.
Далее, Вы перемещаете на данный ресурс изображение с компьютера, по которому нужно распознать текстс картинки. Открывайте его для просмотра с помощью гугл документов. Если всё получилось, то у Вас должен появиться нормальный текст на самом изображении и внизу после загруженного фото. Загрузка файла занимает некоторое время поэтому, немного подождите, прежде чем всё отобразиться. (Рисунок 1)
А вот как распознать текст с фото, в Яндексе читайте далее.
к оглавлению ↑Как распознать текст с фото в Яндексе
Поисковик Яндекс, имеет сервис под названием Яндекс-переводчик. Он помогает не только переводить англоязычные слова, но и может распознать текст онлайн с картинки. Данный инструмент, находится на главной странице браузера Яндекс. Перейдите в него, чтобы загрузить картинку. Затем, откройте данное фото в переводчике, для полного просмотра. (Рисунок 2).
После чего у Вас должен появиться текст, как на русском языке, так и английском. Данные сервисы, помогают разобраться с вопросом, как распознать текст с фото. Теперь, перейдём к программам, если сервисы Вам не помогли.
к оглавлению ↑Программы для распознавания текста с картинки
Программа для распознавания текста с картинки, тоже ничем не хуже указанных выше сервисов. Они выполняют свою работу, эффективно и качественно, делая любые картинки с текстами годными для чтения. Как их использовать? Рассмотрим две программы, которые Вам помогут сделать картинку читаемой:
- Fine Reader. Данная программа, была специально создана для того чтобы распознавать текст с картинки. Работает она аналогичным образом, как и сервисы. Но, с помощью неё, можно сохранять тексты с картинок, в различные виды документов. Например, ПДФ, Ворд и так далее. Она имеет платная, и поэтому не весь функционал у Вас будет доступен.
- Scan Adobe. Это программное средство умеет определять не только обычные картинки, но и целый снимок камеры. Она сохраняет все переделанные изображения только в формат PDF.
В Интернете есть много подобных программ, но эти пользуются большим спросом и им доверяют уже много лет.
к оглавлению ↑Заключение
В этой статье, была дана информация о том, как распознать текст с фото. Данный материал пригодиться и тем, кто зарабатывает через Интернет. Ведь, с приходом опыта, приходиться использовать много инструментов, которые иногда упрощают работу в сети. Удачного Вам распознавания текста!
С Уважением, Иван Кунпан.
P.S.
Для более удобного использования сервисов по распознаванию картинок, рекомендую прочитать статьи (Как пользоваться Яндекс диском, Облако Гугл диск).
Просмотров: 93
Получайте новые статьи блога прямо себе на почту. Заполните форму, нажмите кнопку “Подписаться”
biz-iskun.ru
Распознать текст с картинки онлайн бесплатно
Если вы когда-либо работали в офисе, то Вам наверняка приходилось частенько перепечатывать большой объем электронной информации. И даже если Вы печатаете вовсе не медленно, все равно эта работа отнимает львиную долю вашего свободного времени.
Для устранения этой неудобной ситуации, мы нашли программу – «Fine Reader», которая имеет функцию распознавания текста с картинки и подходит для работы с практически любыми изображениями. Для многих она станет отличным выходом. Однако есть одно, но – данный софт – пиратский, из-за чего, для работы в офисе, он кажется неуместным. Однако есть несколько не менее эффективных онлайн-сервисов, распознающих текст.
Кроме платных сервисов, занимающихся распознаванием текстов на картинках, естественно есть и бесплатные, к рассмотрению которых мы и приступим.
Распознавание текста на www.newocr.com
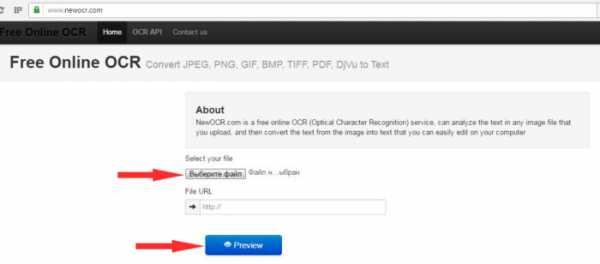
Замечательный сервис, использовать который, можно даже не регистрируясь. Он выполняет работу без каких-либо ограничений и может распознать любую картинку, при этом бесплатно. Сервис работает с 58 языками и сохраняет полученный текст в практически любом общепринятом формате.
Что форма носа может сказать о вашей личности?
Как найти свою вторую половинку: советы для женщин и мужчин
20 Признаков что вы нашли идеального парня
Работа с www.ocrconvert.com

Эта онлайн программа также не запрашивает прохождение регистрации и отлично распознает информацию с фотографий. Для работы с ней, загрузите фотографию формата GIF, PDF, JPEG или BMP, после чего вы получите необходимую ссылку на текстовой файл представленный в виде txt. Затем нужно скопировать его в какой-нибудь удобный для вас вид документа (блокнот, Word, Excel и прочее).
Конвертирование на finereaderonline.com/ru-ru

Еще один профессиональный сайт, который распознает текст в мгновение ока, однако безвозмездная работа возможна всего на десяти сканах. Кроме того, на нем придется пройти регистрацию, что бы начать работу по распознаванию текста. Выберите необходимое фото, поставьте язык и нажимайте по надписи «Распознать».
FineReader — программы для распознавания текста
Как мы писали в начале, есть очень удобная утилита, распознающая текстовые фотографии – FineReader. Вы можете скачать пиратскую версию программы с любого торрент-трекера, но все же советуем вам ее приобрести.
Когда установка программы завершится, откроется следующее окно:
Чего не следует делать в социальных сетях
15 шокирующих пластических операций, завершившихся плачевно
9 самых жутких пыток древнего мира
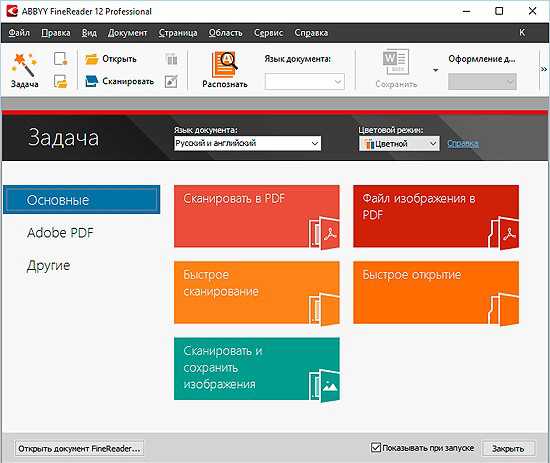
Данный софт также способен распознать любой формат изображения, включая pdf и djvu. Чтобы проверить работу этой программы, мы загрузили с сети скан документа и попробовали распознать его. Для этого нужно перетащить документ, который Вы собираетесь преобразить в текст.
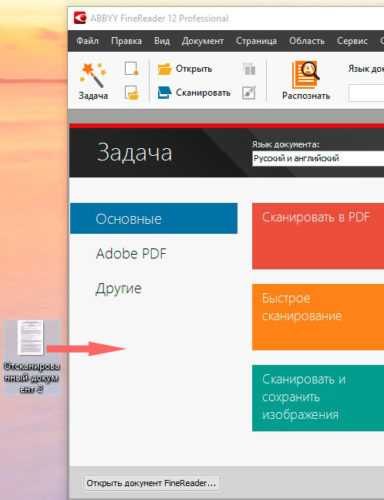
После этого, программы автоматически начнет процедуру распознавания текста с картинки, которую вы добавили. Завершив процесс, который занимает от 10 до 15 секунд, можно сохранять тест в любой удобный формат, например в вордовский документ.
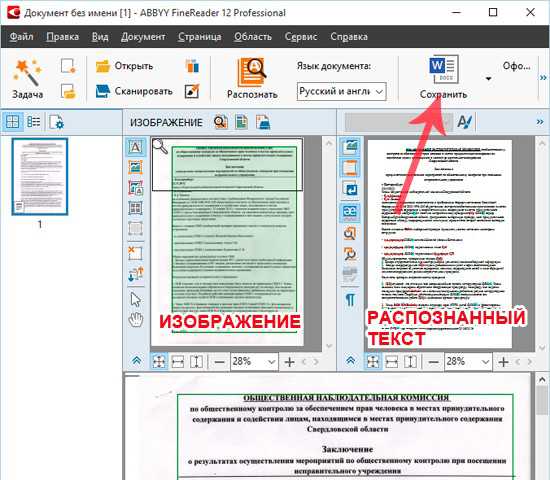
Теперь можно открыть готовый документ в выбранной вами программе.
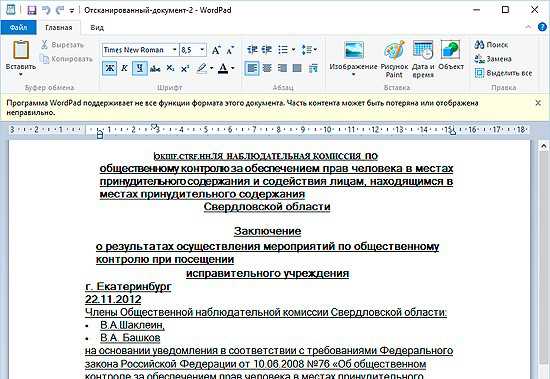
Как видим на изображении, текст превосходно распознается. Программа FineReader на ура выполняет свои функции и практически не имеет конкурентов.
Стоит отметь, что для качественного узнавания отсканированного документа, неважно, на сервисе или с помощью софта, фотография должна быть высокого разрешения. Если, например, вы сделаете фотографию текста на телефонную фотокамеру в 0,3 Мп, то есть вероятность, что текст будет не верным. Поэтому гораздо удобней пользоваться либо хорошей камерой, либо сканером.
uchieto.ru
Поиск. Как “вытянуть” иероглифы из картинки
Попадается картинка с иероглифами, а Вам необходимо знать что там написано.
На помощь придут программы для распознавания текста (OSR).
Что делать по пунктам:
- Сохраните картинку с иероглифами на компьютере
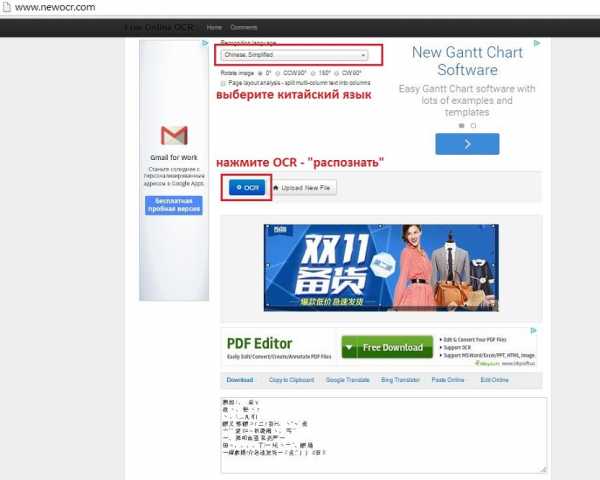
- Откройте онлайн программу для распознавания текста (Free Online OCR), например эту — www.newocr.com
Дальше на сайте онлайн программы Мы:
а) загружаете картинку (Upload new file)
б) выбираете китайский язык (Chinese simplified)
в) выбираете область на картинке которую нужно распознать
г) нажимаете кнопку OSR. Если язык выбран правильно, под картинкой Вы увидите иероглифы. Ура! - Теперь копируем полученные иероглифы в сервис перевода гугла translate.google.com.ua
- и выбираем направление перевода Китайский – Русский. Всё! Текст должен перевестись на русский язык.
Внимание! Если Вы не можете сохранить картинку на компьютер, как вариант — сделайте скриншот экрана или нужной его части (screenshot)
Вот у нас картинка, сохраненная на компьютере
загружаем ее на сайте онлайн сервиса распознавания изображений в текст ( www.newocr.com )
текст который “перевелся” ↑ копируем
открываем translate.google.com.ua и переводим текст
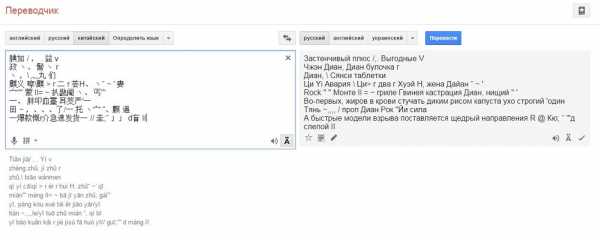
Если перевод содержит ошибки — Увы……
Все равно лучше, чем ничего!
buykitay.com
Онлайн распознавание текста с картинки
В процессе написания реферата, дипломной работы или подготавливая доклад на заданную тему учащийся (абитуриент) использует довольно большие массивы информации. Именно в такие моменты пользователю может потребоваться услуга онлайн распознавание текста с картинки. Ведь зачастую необходимый для работы документ имеет не совсем приемлемый формат, а также может быть в виде скана, картинки или скриншота. В следствии чего, полноценное использование текстового материала с последующим применением основных элементов редактирования просто невозможно без программной поддержки онлайн инструментов, о которых и пойдет речь в этой статье.
Наиболее корректный распознаватель текста — Finereaderonline
Безусловным лидером представленного обзора является именно этот онлайн сервис. И все же, сразу оговоримся, среди бесконечного списка преимуществ данного текстового агрегатора нашлось и место для недостатков.
Существенный минус — это отсутствие бесплатной формы использования. Ограниченный вариант ознакомления с возможностями сервиса все же доступен, если вы пройдете весьма простой процесс регистрации.
В течении 15-ти дней вам дается право «распознать» десять документов. По истечении этого срока, а также исчерпав лимит на обработку данных необходимо купить один из аккаунтов доступа.
Использовать инструмент в работе — https://finereaderonline.com/ru-ru
Совершенно бесплатные сервисы распознавания текста
Таковых во Всемирной паутине невероятное множество. Однако наш выбор должен отвечать следующим критериям:
- Простота и неограниченность в использовании.
- Инструмент обязательно должен поддерживать русский язык.
- Высокий уровень функциональности.
Несмотря на соответствие ниже представленных сервисов упомянутым условиям, все же велика вероятность того, что в результате распознавания вы получите не совсем читабельный текст.
В некоторых случаях придется подкорректировать полученный контент, так сказать вручную. Тем не менее, это все же лучше, нежели руками перепечатывать большие объемы сканированного текста.
Free Online OCR — очень мощный инструмент распознавания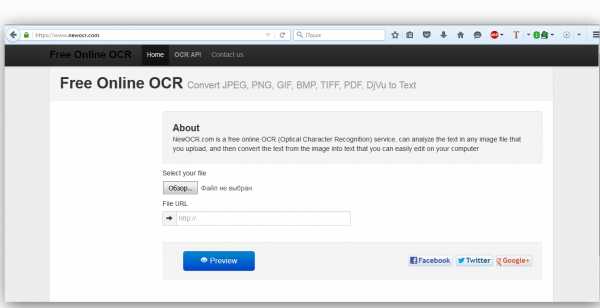
Без регистрации и каких-либо ограничений вы можете производить операции OCR преобразования с файлами следующих форматов: JPEG, PNG, GIF, JFIF, BMP, PBM, PPM, PGM, PCX, а также документов с расширением — TIFF, PDF, DjVu, DOCX, ODT и даже загружать на обработку некоторые ZIP архивы.
Сервис способен распознать 106 языков. Что немаловажно Free Online OCR поддерживает пакетную обработку данных. То есть загрузив многостраничный PDF файл вам останется лишь немного подождать, пока не будет завершен процесс распознавания. Сохранить на ПК полученный результат можно в виде: TXT, DOC, ODT, RTF, PDF или HTML документа.
Хотите попробовать Free Online OCR в действии, вам сюда — https://www.newocr.com/.
i2OCR — самый «объемный» обработчик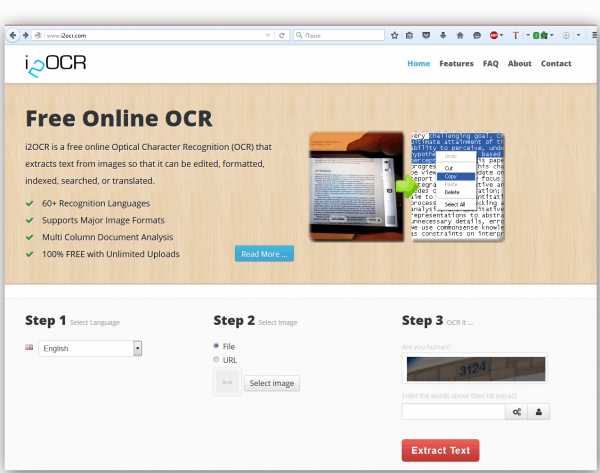
Используя данный веб инструмент, вы сможете загружать картинки и документы размером до 10 МБ. Незначительные неудобства в работе сервиса — это периодический ввод капчи.
Помимо основной функции распознавания i2OCR оснащен несколькими специальными кнопками навигации, посредством которых можно осуществить комфортный переход в определенную область редактирования.
Что касается поддерживаемых форматов графических файлов, то здесь воспринимаются основные и широко применяемые, все те же — JPG — PNG — BMP — TIF — РВМ — PGM – PPM. Вывод итогового документа можно произвести в виде DOC, PDF или TXT файла.
Воспользоваться данным сервисом можно здесь — http://www.i2ocr.com/.
OnlineOcr
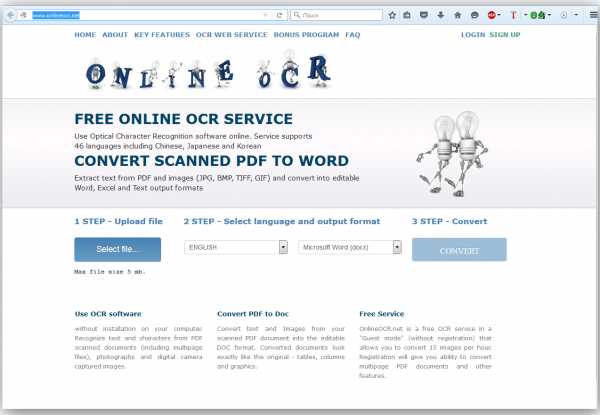
Достаточно быстро функционирующий сервис позволяет в течении одного часа провести распознание 15-ти документов. Размер каждого из них (по отдельности) не должен превышать 5 МБ.
OnlineOcr поддерживает следующие графические форматы: JPEG, TIFF, BMP и GIF.
По завершению операции перевода текста из графического состояния в символьный формат, полученный результат можно сохранить в виде MS Word (DOC) или MS Excel (XLS) документа, а также с расширением TXT.
Попробовать инструмент в работе — http://www.onlineocr.net/
В заключение
Что ж, возможно какой-либо из сервисов вам действительно понравиться и, надеемся, окажется невероятно полезным. Ну а напоследок хочется дать вам, уважаемый читатель, несколько полезных советов. Во-первых, чтобы получить действительно качественный результат — первичный документ должен быть в высоком разрешении. Второе, всегда обращайте внимание на кнопку, где выбирается язык распознавания. Ну и третье, если первая «попытка» не принесла ожидаемого результата, то стоит попробовать другой вариант и даже следующий. В любом случае, знайте — безвыходных ситуаций не бывает!
pcmind.ru
Онлайн-сервисы для распознавания текста / Программное обеспечение
Как только человек изобрел компьютер, он стал переносить в него свои знания. Поскольку главным носителем знаний до появления компьютерной техники были книги, возникла задача – каким образом накопленную информацию можно быстро перевести в “цифру”? Глупо было бы использовать для этого самый простой и очевидный способ перевода книг в цифровой формат – набор вручную. Человечество тысячелетиями накапливало различные тексты, поэтому процесс их повторного “написания” занял бы невероятно много времени. Для решения этой задачи необходимо было найти какой-то простой и эффективный способ автоматизации процесса повторного набора текста. Так возникли различные технологии оптического распознавания текста или сокращенно OCR (optical character recognition). В наши дни с процедурой перевода машинописного листа в текстовый документ знаком каждый студент и школьник. Печатный текст сканируется (или фотографируется), затем с помощью специального программного обеспечения компьютер анализирует снимок текста, выделяет на изображении отдельные элементы и создает новый документ, в который заносит все распознанные буквы и символы. Такой документ, как правило, является редактируемым, благодаря чему можно исправлять ошибки машинного распознавания и работать с ним как с набранным текстом. В зависимости от сложности исходного текста и качества отсканированного изображения, процесс обработки документа OCR-приложением занимает больше или меньше времени. К счастью, сегодня процедура перевода набранного текста в формат электронного документа занимает намного меньше времени, чем несколько лет назад – аппаратные возможности компьютеров за последние десять лет заметно увеличились, а благодаря постоянным усовершенствованиям алгоритмов анализа изображения процент ошибок стал намного меньше. Более того, теперь распознавание текста можно доверить даже онлайновым сервисам, преимущества которых перед обычными настольными приложениями очевидны – не нужно раскошеливаться на дорогостоящее ПО и тратить время на установку приложения. Наконец, используя для распознавания онлайновые средства, можно получить редактируемый текст из снимка даже на таких компьютерах, где просто нет возможности устанавливать программы, например, на публичном ПК в библиотеке. Начнем с онлайнового сервиса компании ABBYY. Нет ничего удивительного в том, что она использует в качестве системы для распознавания текста популярную программу FineReader. В рекламе этот продукт не нуждается – сегодня это приложение можно считать одним из лучших вариантов OCR. Причин успешного продвижения этой программы очень много. Прежде всего, это отшлифованный алгоритм идентификации печатных символов. Движок самой популярной системы оптического распознавания текста, FineReader, совершенствовался годами, механизм анализа изображения улучшался от версии к версии. В программу вносились различные изменения и улучшения, которые уменьшали количество нераспознанных или некорректно определенных символов при обработке сканированного изображения. FineReader включает в себя множество средств и вспомогательных инструментов, которые дают возможность выполнить тонкую настройку программы, улучшить качество исходного изображения, определить тип распознаваемых символов, установить области для обработки и т.д. Онлайновый сервис является бесплатным проектом, который дает возможность пользователям оценить точность работы FineReader. Одно из его главных достоинств – поддержка большого количества определяемых языков (всего доступно 37 языков). Для того чтобы воспользоваться сервисом, необходимо пройти регистрацию. Поскольку этот проект носит отчасти рекламный характер, возможности распознавания текста в нем существенно ограничены. Во-первых, анализ изображения происходит в полностью автоматическом режиме. Пользователь может лишь указать язык распознавания и включить опцию, которая позволит получить ссылку на результат распознавания на введенный адрес электронной почты. Во-вторых, объем файла, загружаемого на сервер, не должен превышать 10 мегабайт. Но самое неприятное ограничение – небольшое количество документов, которое можно распознать. Зайдя под одной учетной записью, можно обработать не более десяти файлов. Однако и это, согласитесь, неплохо. FineReader Online может также обрабатывать тексты, содержащие любые комбинации поддерживаемых языков. При этом сервис не позволяет выбирать более трех языков распознавания для одного документа. Разработчики мотивируют это тем, что подобная функция существенно замедлила бы процесс распознавания текста. Готовый результат распознавания текста может быть сохранен в один из форматов – MS Word (.doc), MS Excel (.xls), PDF, PDF/A, RTF и TXT. В принципе, сервис справляется с поставленной задачей и определяет текст. Однако, справедливости ради, следует сказать, что даже очень хорошее качество исходного изображения не дает стопроцентной гарантии распознавания. Даже такое “идеальное” изображение, как скриншот всплывающей подсказки на странице сервиса, FineReader Online распознал с ошибками. ocrNow! – британский сервис, который также использует в качестве системы для распознавания текста FineReader. Уже на этапе регистрации можно выбрать формат, в котором по умолчанию будут сохранены данные – RTF, PDF, XLS, XLM, TXT или Web Archive. Изменить формат можно при загрузке каждого нового файла. Кроме этого, есть возможность получить текст по почте. Стоит отметить, что результаты могут быть запакованы в ZIP-архив, благодаря чему время на загрузку полученного файла сократится. Сервис поддерживает загрузку изображений в форматах TIF, PNG и JPG (JPEG), а также PDF. Кроме этого, можно загрузить ZIP-архивы, содержащие файлы поддерживаемых типов, и они будут распакованы и обработаны автоматически. ZIP-архив удобен не только тем, что позволяет уменьшить размер файлов, которые необходимо загрузить на сервер, но и тем, что благодаря ему можно загрузить несколько файлов за один раз. ocrNow! работает с шестнадцатью языками, в том числе с документами на русском английском, французском, чешском, испанском, итальянском. Выбор языка осуществляется при загрузке файла. Даже если не указать язык, сервис попытается определить его автоматически, правда, не исключено, что он ошибется, поэтому лучше все же выбрать язык вручную. Стоит заметить, что выбрать можно лишь один язык. Каждому зарегистрированному пользователю предоставляется два бесплатных кредита, которые можно использовать для распознавания двух страниц формата A4. Если необходимо работать с большим количеством данных, необходимо купить кредиты. Их стоимость зависит от того, сколько кредитов вы решите приобрести за один раз. Например, если купить 20 кредитов, то распознавание одного листа A4 обойдется в 0,1 фунта стерлингов (около 4,6 рубля), а если приобрести сразу 500, то стоимость распознавания одного листа снизится примерно до 2,96 рубля. Создатели сервиса предлагают специальную утилиту, позволяющую использовать его совместно с Apple iPhone. При помощи этой программы можно фотографировать документы, а затем отсылать их на сервис и получать результаты. Бесплатная версия этой программы дает возможность обработать десять фотографий, а коммерческий вариант, снимающий это ограничение, обойдется в 14 долл. Пользователям, которые часто обращаются к услугам сервиса со своего настольного компьютера, предлагается скачать утилиту Unimessage Solo, предназначенную для сканирования файлов. Особенность этой программы в том, что в ней реализована интеграция с сервисом ocrNow! Кроме этого, созданные с ее помощью файлы можно загрузить на Facebook. Данный сервис является коммерческим. Для работы с ним необходимо приобретать кредиты, каждый кредит – возможность распознавания одной страницы документа. Однако даже в демонстрационном режиме с его помощью можно переводить небольшие фрагменты текста. Сервис предлагает очень удобную загрузку файлов – на сервер можно загружать одновременно несколько изображений, упаковав их в ZIP-архив. Максимальный размер файла – 20 мегабайт, но можно использовать и файлы большего размера, однако для получения такой возможности необходимо связаться с администрацией сервиса. В качестве исходного формата графического файла можно использовать TIFF (поддерживаются в том числе и многостраничные документы), JPEG/JPG, BMP, PCX, PNG, GIF, PDF. Если с помощью данного сервиса распознается многостраничный документ, например, PDF, можно указать только отдельные страницы для распознавания. Для этого в настройках распознавания необходимо установить флажок напротив “Многостраничный документ” и в поле для диапазона страниц указать необходимые страницы через запятую (или диапазон страниц через дефис). Если указать, скажем “4,13”, сервис распознает только четвертую и тринадцатую страницы. В демонстрационном режиме сервис OnlineOCR.ru распознаёт не весь текст, а только его часть. Всего сервис поддерживает 28 языков, включая русский, английский, белорусский, венгерский, голландский, греческий, датский, испанский, латвийский, латинский, немецкий, польский, шведский, финский, французский, украинский и др. Сервис позволяет хранить файлы с результатом распознавания в виртуальном рабочем кабинете online, редактировать, отправлять их по почте и выводить на печать. Проект NewOCR.com не требует ни регистрации, ни дополнительных денежных трат со стороны пользователя. Сервис имеет минималистический интерфейс, и его настройки сводятся к выбору языка. Если загруженное изображение имеет неправильную ориентацию, например, повернуто в процессе сканирования на 90 градусов, в выпадающем меню сервиса можно установить угол поворота картинки. Качество обработки графического файла оставляет желать лучшего – конечный документ содержит многочисленные ошибки распознавания, поэтому вряд ли стоит использовать этот сервис для обработки большого числа страниц. Этот недостаток несколько смягчает то обстоятельство, что проект поддерживает работу с 29 языками (включая русский). Распознавать можно изображения в форматах JPEG, PNG, GIF, BMP, а также многостраничные файлы TIFF. Размер файлов не должен превышать пять мегабайт, а для многостраничных PDF-документов лимит составляет 20 мегабайт. После обработки отсканированного изображения сервис продемонстрирует результат в отдельном поле, рядом с копией загруженного изображения. Распознанный текст можно экспортировать в формат .doc или .txt. Этот сервис можно использовать бесплатно, причем регистрация не требуется. Для защиты от спама используется контрольное изображение (Captcha). Однако, выбрав этот сервис для обработки своих файлов, следует учитывать ограничения, которые касаются обрабатываемых изображений. Так, размер загружаемых на сервер файлов ограничен двумя мегабайтами. Еще одно ограничение сервиса, которое касается загружаемых файлов, – разрешение каждого из графических изображений не должно превышать 5000 точек по ширине. Кроме этого, Free-OCR.com устанавливает лимит на количество обработанных документов. В час можно загрузить не более десяти изображений. На данный момент сервис не умеет распознавать многостраничные документы PDF или TIFF, поэтому при обработке таких файлов распознается только первая страница. Сервис позволяет обрабатывать страницы с многочисленными столбцами текста. В настройках Free-OCR.com нельзя выбрать более одного языка, поэтому, если попробовать распознать, например, русский текст с английскими терминами, ошибок будет предостаточно. Общее количество поддерживаемых языков, которые можно выбирать для распознавания, довольно много – двадцать девять, в том числе и русский. Качество распознавания документов удовлетворительное.⇡#Заключение
Далеко не все услуги онлайновых сервисов для распознавания текста предоставляются бесплатно. Однако цена, которую просят их создатели, заметно ниже стоимости специализированного ПО. Естественно, если вам необходимо распознавать десятки документов ежедневно, то платить создателям онлайнового сервиса для вас вряд ли будет выгодно – гораздо дешевле будет один раз заплатить за лицензию программы. Но если вы пользуетесь подобными средствами лишь время от времени, то проще заплатить за распознавание необходимого числа страниц или попытаться обойтись полностью бесплатными сервисами.Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
3dnews.ru
Распознавание текста с картинки онлайн в Google Docs и FineReader
Вам нужно распознать текст, а необходимой программы нет под рукой? Что делать и как быть в такой ситуации? Выход есть – бесплатное распознавание текста онлайн с картинки в Google и FineReader. Об этом и пойдет речь в данной статье.
Качество распознаваемого текста может отличаться у разных онлайн сервисов. На него влияет и исходный материал: фотография или сканированное изображение. Выбор лучшего сервиса остается за вами. Далее мы рассмотрим работу некоторых из них, отвечающих следующим параметрам:
- Бесплатное распознавание текста (или условно бесплатно)
- Русский интерфейс

Распознавание текста с картинки в Google Docs
Google Docs – online офис, включающий в себя бесплатное оптическое распознавание текстов документов (OCR). Сервис может работать с различными форматами: JPEG, GIF и PNG, размер которых не превышает 2 МБ. Он поддерживает многостраничные PDF-файлы (до 10 страниц).
Для работы в документах Гугл нужна учетная запись. Если у вас её нет – зарегистрируйте почтовый ящик в Google. Этого будет достаточно для доступа ко многим его сервисам.
В качестве примера возьмём скриншот одной из предыдущих статей сайта, — его мы и будем распознавать.
Войдите в Google Docs (ссылка дана выше) под своим логином и паролем от почты Гугл.
В правом верхнем углу найдите иконку в виде шестерёнки (настройки), перейдите в «Настройки загрузки» и отметьте галочками все пункты.
Затем нажмите на иконку загрузки – «стрелка вверх» (расположена слева) и выберите пункт «Файлы». В открывшемся окне укажите путь к картинке и нажмите «Открыть». Прежде, чем изображение поместится в ваш «Google диск» вы увидите диалоговое окно с настройками загрузки.
Возможно, кто-то из вас спросил бы: а зачем мы тогда на предыдущем шаге настраивали загрузку, если снова появляется окно с её настройками? Всё дело в том, что теперь, помимо тех же настроек, что и в главном меню, предлагается выбор языка документа.
Собственно, так выглядит диалоговое окно при добавлении нового файла (рисунок ниже).
Выберите язык документа, в данном случае это русский, и нажмите «Начать загрузку». Через некоторое время отобразится ваш документ.
Щелкните по нему правой кнопкой мыши и выберите «Открыть с помощью» — «Google документы».
В следующем окне откроется онлайн офис. Сверху отобразится изображение, а снизу распознанный текст.
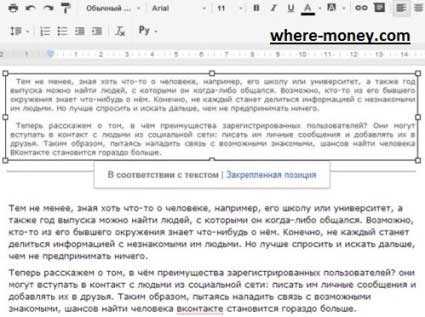
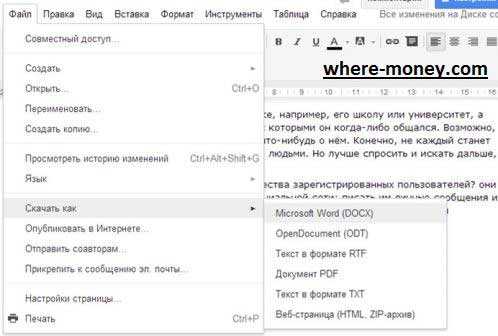
Изображение можно выделить и удалить, оставив лишь текст. Чтобы сохранить документ на компьютер – перейдите в раздел меню «Файл» — «Скачать как» — выберите подходящий формат.
С одним сервисом разобрались, теперь перейдем к следующему.
ABBYY FineReader Online
FineReader Online – сервис компании ABBYY. Он обладает вполне высоким качеством распознавания текстов, однако, это коммерческий продукт. Бесплатно распознать можно только 3 страницы текста, после чего предлагается купить данную услугу.
Перейдя по указанной выше ссылке, нажмите на FineReader Online. Затем откроется окно с возможностями этого сервиса. Выберем «Извлекайте текст из цифровых фотографий».

Чтобы работать в сервисе, нужно зарегистрироваться в нём.
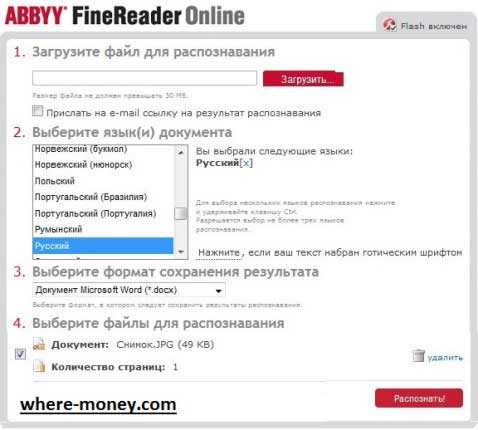
Загрузите файл и выберите язык документа. Затем укажите формат сохранения результатов и жмите «Распознать».
Через некоторое время картинка будет распознана. В следующем окне можно сохранить документ, кликнув по нему мышью, или распознать следующий файл.
Если вам нужен бесплатный инструмент — выберите Google Docs. Хоть он и имеет весьма специфический интерфейс, в нем можно разобраться.
where-money.com